
刷脸签到系统回顾
毕设 👉 南师大刷脸签到系统 👉 face.moyuyc.xyz

写该文是为了准备写毕业论文的材料,所以文字介绍较多,比较面向大众程序员。
任务概要(Task Summary)
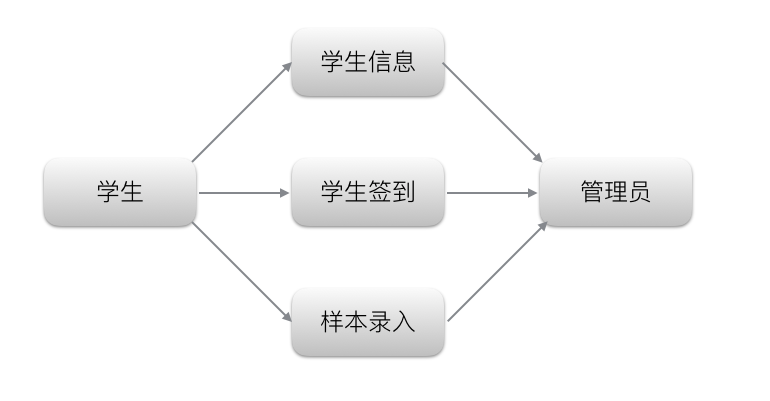
本刷脸系统主要分为学生签到、人脸录入、管理员模块。管理员模块,可以对学生的人脸样本,学生相信操作;该系统核心模块:学生签到,将动态监控摄像头,一旦识别出人脸便向服务器发出请求进行预处理 => 人脸检测 => 人脸比对。该系统将采用 Web 架构实现,前端使用react+redux+router+webpack技术栈,结构清晰,复用率高;后端将采用 nodejs+express 搭建服务器,C++ 实现核心人脸识别比对算法,通过 js 调用 C++ 核心算法;后续可以使用 electron 将前端界面打包成跨平台app,方便师生使用。
技术栈(Technology Stack)
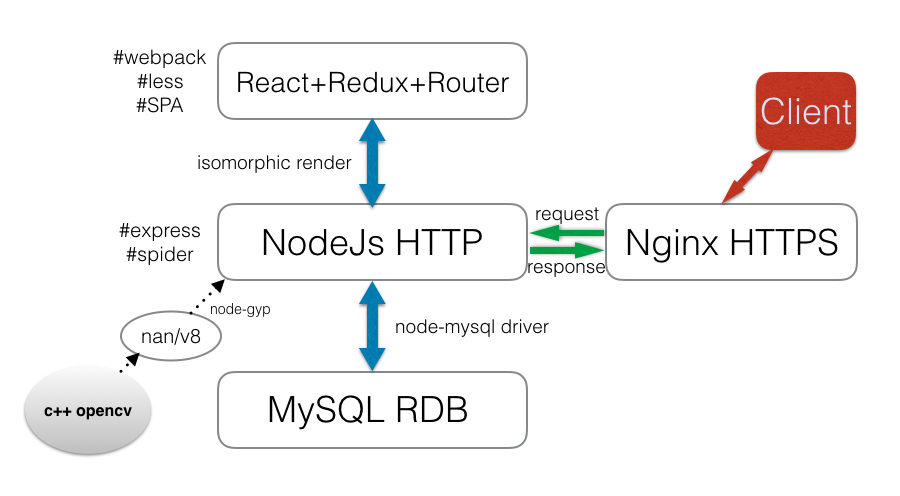
下面进行一些较为粗略的介绍,蜻蜓点水说说涉及的技术
前端(Front-End)
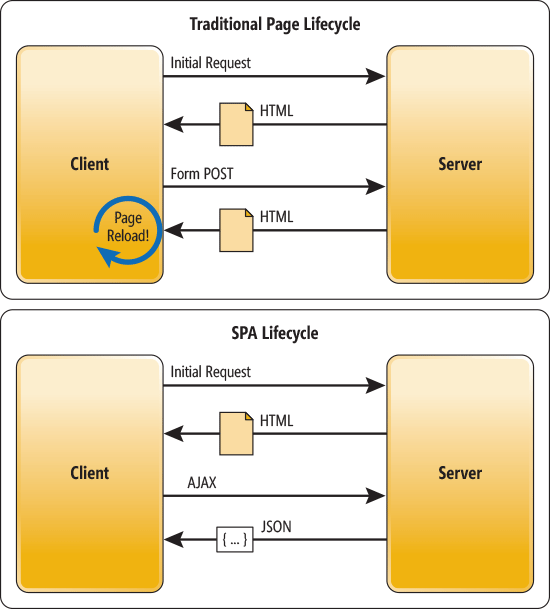
单页Web应用(single page web application,SPA),就是只有一张Web页面的应用。单页应用程序 (SPA) 是加载单个HTML 页面并在用户与应用程序交互时动态更新该页面的Web应用程序。 浏览器一开始会加载必需的HTML、CSS和JavaScript,所有的操作都在这张页面上完成,都由 JavaScript 来控制。因此,对单页应用来说模块化的开发和设计显得相当重要。
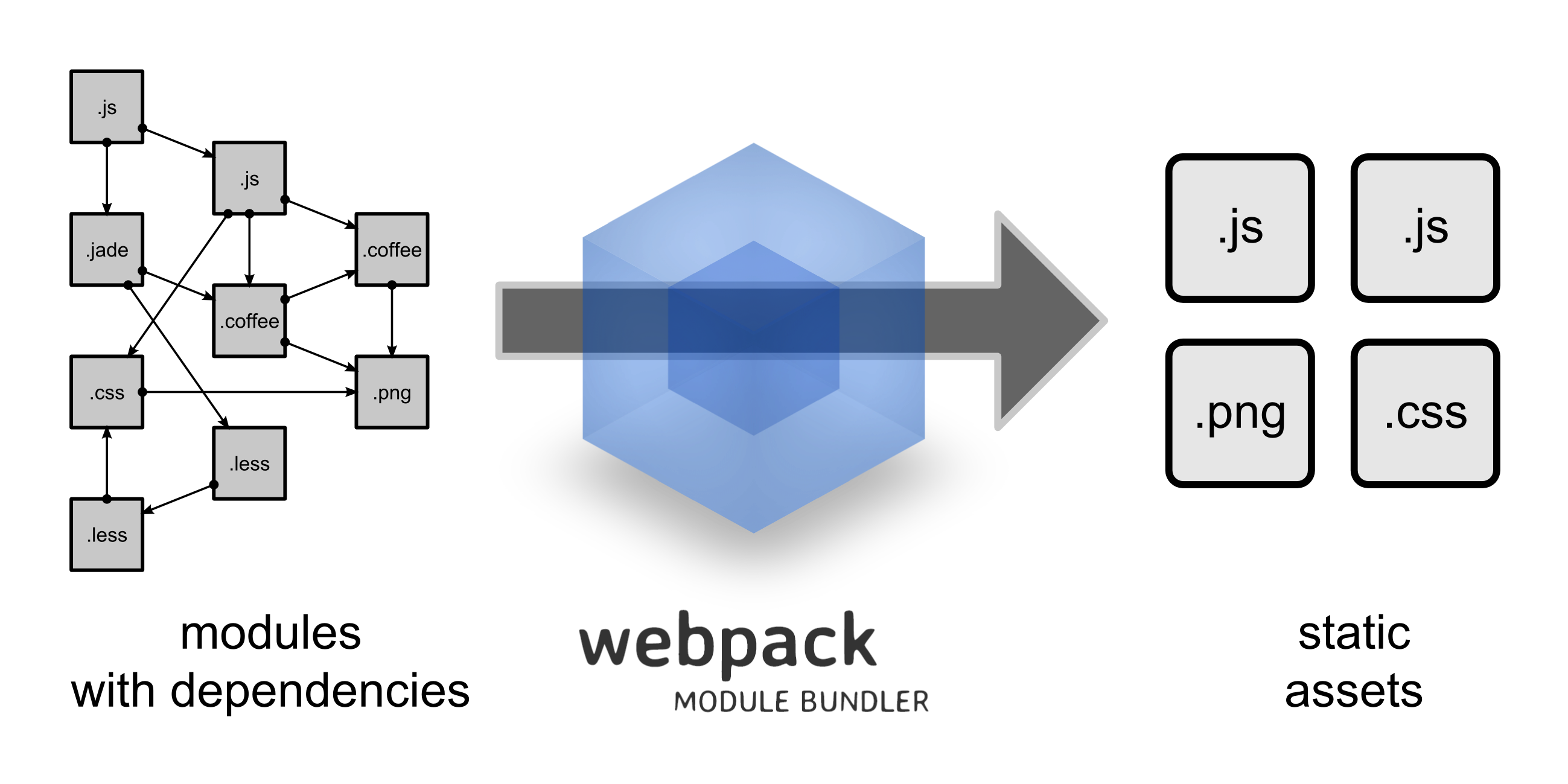
使用主流 Webpack 构建,进行前端模块自动化管理。
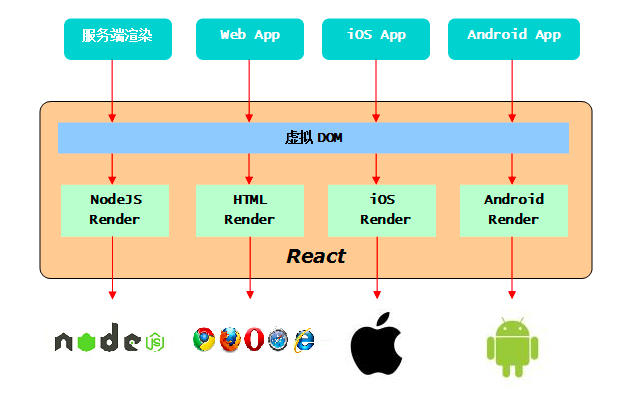
使用Facebook提出的 React 进行作为 View, 将 HTML DOM 进行上层抽象,提出 Virtual DOM 概念,一套理念,实现了Server render, Web UI, mobile UI 的统一。 Learn Once, Write Anywhere
Redux,随着 JavaScript 单页应用开发日趋复杂,JavaScript 需要管理比任何时候都要多的 state (状态),state 在什么时候,由于什么原因,如何变化已然不受控制。 当系统变得错综复杂的时候,想重现问题或者添加新功能就会变得举步维艰, Redux则是为了解决该痛点而产生。
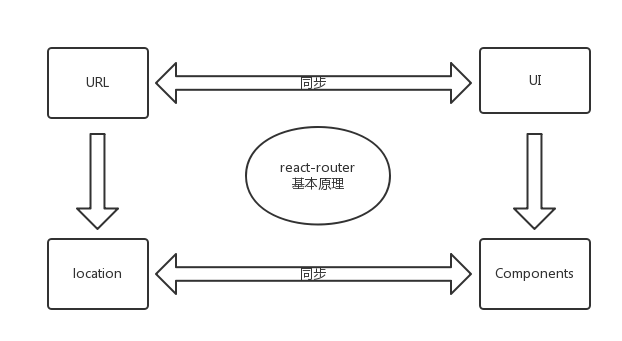
React Router 是一个基于 React 之上的强大路由库,它可以让你向应用中快速地添加视图和数据流,既保证了单页应用的畅快,同时保持页面与 URL 间的同步。
*Babel => 使用 JavaScript 实现的编译器,正如官网所说的那样 Use next generation JavaScript, today. ,可以利用 Babel 书写最新的 JavasScript 语法标准,如 ECMAScript 6 ,搭配 Webpack 使用更佳。
*ECMAScript6 => 2015 年提出的JavaScript标准,目标是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。ECMAScript和JavaScript的关系是,前者是后者的规格,后者是前者的一种实现。ES 6 具有一系列简明的语法糖,更佳的书写体验。但为了保证浏览器, Node 环境兼容性,往往配合 Babel 书写。
*less => 一种 CSS 预处理语言,增加了诸如变量、混合(mixin)、函数等功能,让 CSS 更易维护、方便制作主题、扩充。
使用 HTML5 的 getUserMedia 方法,调用计算机音频视频等硬件设备。为了安全问题,Chrome 只能在本地地址上调用该方法,外网地址则只能在通过证书检测的 HTTPS 服务中调用。
后端(Back-End)
- 采用 nodeJs 作为后端,采用 JavaScript 脚本语言开发。 nodeJs 具有异步事件驱动、非阻塞(non-blocking)IO 特性,采用 Google 的 V8 引擎来执行代码。
- Node.js以单线程运行,使用非阻塞I/O调用,这样既可以支持数以万计的并发连接,又不会因多线程本身的特点而带来麻烦。众多请求只使用单线程的设计意味着可以用于创建高并发应用程序。Node.js应用程序的设计目标是任何需要操作I/O的函数都使用回调函数。 这种设计的缺点是,如果不使用cluster、StrongLoop Process Manager或pm2等模块,Node.js就难以处理多核或多线程等情况。
- pm2 => https://segmentfault.com/a/1190000004621734
- isomorphic render(同构渲染)=> 指的是前后端使用同一份代码。前端通过 Webpack 实现 CommonJs 的模块规范(Node亦是 CommonJs )+ React 提出的 JSX ,使得 NodeJs 通过解析请求的 URL,适配 react-router 中的前端路由规则,得到 routing Props,还可以 dispatch(action) 同步或异步(一般是 isomorphic-fetch ),又或是直接读取数据,从而更新 store ,最后 nodeJs 通过 store 中的 state 渲染 JSX ,产生静态的 HTML,从而实现了前后端的同构渲染。
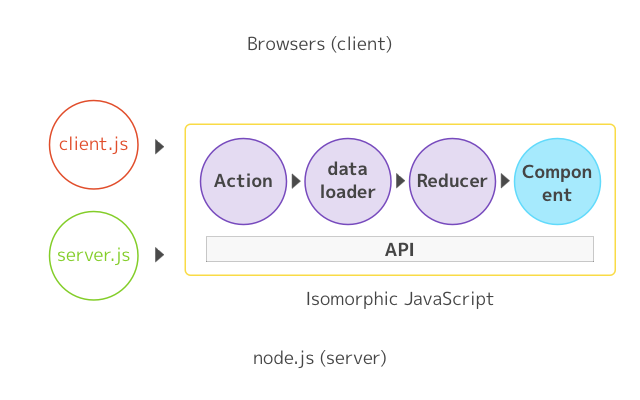
- nodeJs C++ Addons,nodeJs 就是使用C++语言实现的,图像处理最强大的库 opencv 便是用 C++ 实现的,这就不得不需要 nodeJs 与 C++ 之前通信,通过 nodeJs 调用 opencv 的方法,node-opencv 便是利用 nan (解决平台间兼容性问题,将异步事件驱动封装)与 v8 (javascript 对应的数据类型与 C++映射) ,通过 node-gyp 工具,将 C++ 打包成 一个动态链接库 *.node,通过 require 即可调用。
- node-mysql ,由于 NodeJs 具有 non-blocking IO 与异步事件驱动的特性,所以很适合于 IO 密集型高并发业务,而访问数据库正是常用的 IO 操作。
- NPM(全称Node Package Manager,即node包管理器),是Node预设的,通过国内 taobao 镜像可以加快下载速度。
- Express(Node.js Web 应用程序框架),很方便的定义 restful api.
- Spider,网络爬虫,通过转发客户端的 HTTP 或 HTTPs 请求,得到远程服务器的响应数据,然后再一次转发至客户端中,也就是代理的意思 关于南师大的一些 API ,已经有前人用 Python 写过了,爬取教务系统数据,然后我只需要爬取对应的网站即可。
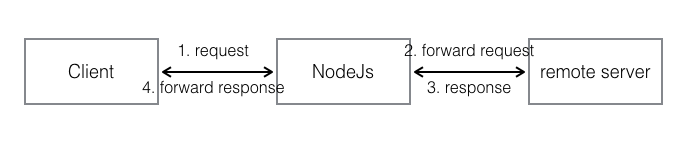
- nginx,使用 C++ 实现的 Web 服务器,通过简单的配置就可以反向代理至正确的端口和应用层协议。
- 由于浏览器安全性的考虑,对于外网地址使用摄像头需要在安全的HTTPs协议下,因此需要付费或免费地得到认可的证书,通过 nginx 配置,反向代理至 Node 进程即可。
其他(Other)
- git 是用于 Linux 内核开发的版本控制工具。与 CVS、Subversion 一类的集中式版本控制工具不同,它采用了分布式版本库的作法,不需要服务器端软件,就可以运作版本控制,使得源代码的发布和交流极其方便。 git 的速度很快,这对于诸如 Linux 内核这样的大项目来说自然很重要。git 最为出色的是它的合并追踪(merge tracing)能力。
- GitHub 是一个通过 Git 进行版本控制的软件源代码托管服务,是全球最大的代码存放网站和开源社区。
- 特征脸(Eigenface)是指用于机器视觉领域中的人脸识别问题的一组特征向量。这些特征向量是从高维矢量空间的人脸图像的协方差矩阵计算而来。一组特征脸 可以通过在一大组描述不同人脸的图像上进行主成分分析(PCA)获得。任意一张人脸图像都可以被认为是这些标准脸的组合。另外,由于人脸是通过一系列向量(每个特征脸一个比例值)而不是数字图像进行保存,可以节省很多存储空间。
- 主成分分析(Principal components analysis,PCA)是一种分析、简化数据集的技术。主成分分析经常用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。
- OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV用C++语言编写,它的主要接口也是C++语言。
涉及知识(Knowledage Involved)
- javascript / react / redux / react-router / webpack / less / node / babel / es6 / tracking.js / isomorphic / promise
- http / https / express / mysql
- opencv / Eigenfaces FaceRecognizer / node addons 降维、特征提取、特征比对
- homebrew / curl / bash script / electron / cross-env / npm script / screen command / pm2 / nginx / git / seo
- 搜索引擎优化(search engine optimization,SEO),是一种通过了解搜索引擎的运作规则来调整网站,以及提高目的网站在有关搜索引擎内排名的方式。所谓“针对搜索引擎作最优化的处理”,是指为了要让网站更容易被搜索引擎接受。
不仅仅局限与以上。以上工具、理论、技术可能只是项目简单地使用,或是学习过程中触碰过而已。
学习记录(Learning Record)
2016年12月9日
- 初步确定课题:基于南师大本科生学生照片,进行人脸识别+特征提取+人脸相似度对比,判断输入人物图片是否存在于库中。若时间允许,精力有余,考虑加上声音比对,提高识别正确率。
- 成功下载南师大本科生照片,代码见
gp-image-download文件夹,使用bash脚本+node实现,可以方便的跨平台。
2016年12月10日
初步了解人脸识别检测。 产生怀疑: 1. 纯粹自己实现系列识别,特征提取,模式匹配等等。仅是识别算法理论,需要的数学功底较复杂...数学已经丢的差不多了..进度缓慢,无法入手,恐怕较难完成。 2. 调用opencv接口或者调用网上api,恐怕工作量不够(应用交互设计完备点?) 3. 换个课题?备选moka(1)或者iNjnu App(2)
2016年12月11日
搭建学生签到系统开发环境,采用
react + redux + react-router + webpack技术栈,利用web前端技术实现界面,后续可以使用electron打包为跨平台app注册
face++账号,打算采用第三方人脸识别比对api
2016年12月12日
初步开发前端页面+后端服务(node express), 前后端分离
使用
Sublime编辑器,默认缩进为Tab,书写脚本updateIndent.js,批量修改Tab为四空格课题确定,《南师大学生刷脸签到系统》 对于人脸识别+比对方面实现,初步考虑3个解决方案:
人脸识别+比对算法完全自己实现。
调用opencv人脸识别api + 自己实现人脸比对算法。
调用网上较成熟的人脸识别+人脸比对接口,如Face++。 以上三种解决方案工作量递减(或者工作量可以在系统功能完备性方面体现),但是识别比对准确率递增。
不知道老师对以上三种方案有什么看法。 如果采用1或2,本人不知道应该看什么相关书籍入门(数学已经丢的差不多了,非考研党),以及所用时间和最终效果都可能不尽人意。
还有一个问题:面向学生的教务系统好像没有输入课程号,教师ID,输出全部选课学生ID的接口。或者在面向教师的教务系统才有提供,但我没有教师账号密码,不能自己爬取。不知道我应该联系谁,才可以提供该接口。
- 获取学号接口
- 根据爬取的学生照片,创建数据库stu(id, audio), sign(id, time, stu_id); 班级的判断,通过已经得到ids.txt前6位得到(去掉非纯数字的,位数不同的)
- 构思管理员入口 => 登录(判断是否已经登录) => 查看学生信息(根据学号,姓名,班级号) + 签到信息查看
2016年12月13日
- 重拾数学 积分 方差 协方差 [统计独立] 矩阵 协方差矩阵*(写得好)
- 方差描述的是它的离散程度,也就是该变量离其期望值的距离。
- 协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
- face_camera (Js人脸检测插件,去掉手动拍照,监控摄像头识别人脸,可以根据searching和是否有人脸进行对比操作,只发送多个人脸部分图像)看下源码,学习识别算法
2016年12月14日
opencv install:
brew tap homebrew/science brew install opencvinstall-opencv-3-on-yosemite-osx-10-10-x linux_install install-opencv-3-0-and-python-2-7-on-osx
brew更改源 替换formula 索引的镜像(即 brew update 时所更新内容)
cd "$(brew --repo)" git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core" git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git brew update替换Homebrew 二进制预编译包的镜像
echo 'export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles' >> ~/.bash_profile source ~/.bash_profile
2016年12月16日
- 使用node-opencv检测人脸,挑选出效果相对好的分类模板
lbpcascade_frontalface.xml, 对比效果数据见backend/data/summary.json - 死嚼PCA理论1, 2
2016年12月18日
- 人脸检测模式匹配数据xml2json(需VPN)
- 发现人脸识别效果不佳,分析原因, 第一,样本每个人只有一张 ,第二,几年下来,人的变化比较大。
- 新增样本输入模块,学生自主输入删除样本。(需要重新训练,存储)
- 采用opencv Eigenfaces 人脸识别算法
2017年1月11日
image-download去除对wget依赖,改用curl指令下载
2017年1月16日
/usr/local/bin/mysql.server start启动mysql开始
mysql数据库设计:face_import table, 书写DAO代码简化部分业务逻辑,删除非必须输入情况(本地图片,网络图片)
考虑到数据的迁移简便和服务器负载,使用
sm.ms免费图床,存储用户导入的人脸图片完成100%人脸录入逻辑。TODO: 每次启动服务器需要读取数据库,得到smms图片数据,进行训练。(为了保证Dev环境启动速度,暂时不做)
引入
cross-env:跨平台设置环境变量NPM包, 区分Dev(父进程监听js文件改动,改动后则重启服务器)与Production环境
2017年1月17日
改善训练样本方法,加上了smms外链的图片训练(一大串Promise)
完成前后端分离的管理员登录状态控制(本地存储+md5编码),完成管理员样本查看功能。
2017年1月18日
- 完成每次启动服务器需要读取数据库,得到smms图片数据,进行训练。
- 完成删除/添加人脸样本,重新训练逻辑(异步,不保证实时性)。
- 对于学生证照,
lbpcascade_frontalface, scale=1.95左右人脸检测效果较好 - distance convert to precentage
- confidence<?, 认为是正确
- 整体大致已经完成,阈值的确定尚未完成
- iterm2, 快捷键设置(useful!)
2017年1月19日
- Server读取app代码时,node_module回环加载,出现错误,修改成只使用最外层node_modules
- react Server端渲染,require() 样式文件的解决方法?(ignore, only无效)
HTTPs才能使用摄像头,因此搞了个免费证书,配置下nginx
mac迁移到ubuntu一系列的问题
- nativefier => 站点打包成App解决方案,
ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ - app:packager scripts
"app:mac64": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -a x64 -p mac --name \"南师大刷脸签到\" \"https://face.moyuyc.xyz/\" -i logos/logo.icns --disable-dev-tools --disable-context-menu",
"app:mac32": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -a ia32 -p mac --name \"南师大刷脸签到\" \"https://face.moyuyc.xyz/\" -i logos/logo.icns --disable-dev-tools --disable-context-menu",
"app:win32": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -p win32 -a x64 --name \"南师大刷脸签到\" \"https://face.moyuyc.xyz/\" -i logos/logo.png --disable-dev-tools --disable-context-menu",
"app:win64": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -p win32 -a ia32 --name \"南师大刷脸签到\" \"https://face.moyuyc.xyz/\" -i logos/logo.png --disable-dev-tools --disable-context-menu"
2017年1月20日
- 同构渲染(优化seo+首屏渲染) css module打包的解决方案, webpack-isomorphic-tools
- 远端发布 screen指令
2017年1月21日
- google+baidu 收录,添加 robots.txt 与 sitemap.txt,如今在google下搜索
南京师范大学 刷脸即可
系统剖析(System Analysis)
源码地址:Graduation-Project
文件结构(Directory Tree)
顶层文件结构如下
Graduation-Project/
├── desktop/
├── gp-image-download/
├── gp-njnu-photos-app/
└── gp-njnu-photos-backend/
desktop/ 中放的是将站点打包成 PC Desktop 的 Logo,logo.icns 用在 osx 系统中,logo.png 则用于 linux 与 windows 系统中,打包成的 PC Desktop 默认也是放在该文件夹下。
desktop/
└── logos/
├── logo.icns
├── logo.ico
└── logo.png
gp-image-download/ 文件夹里面放的是将教务系统的学生图片下载至该文件夹中,其中的 data/ 文件夹放的是各年入学的学生的学号(部分学号不正确),数据是 get-all-id.js 脚本得到,具体工作细节在后面会说到。保证获取到各年的学生学号集后,通过 download.sh Bash 脚本即可进行下载;下载的图片放在 images/ 中。
gp-image-download/
├── data/
│ └── ...
├── download.sh
├── get-all-id.js
├── images/
│ └── ...
└── lib/
└── get-all-id.js
gp-njnu-photos-app/ 放的是前端代码,app/ 是开发用的源码,build/ 是用 Webpack 打包的压缩后的发布资源,包括 css/js/html/image...
gp-njnu-photos-app/
├── app/
│ └── ...
├── build/
│ └── ...
├── index.js
├── package.json
├── webpack-assets.json
└── webpack.config.js
gp-njnu-photos-backend/ 放的是后端的全部代码。
cpptest/c++ opencv 的一些测试test/nodejs 调用 opencv 接口的例子data/放些人脸 xml 模板数据,服务器运行时生成的缓存数据,预处理后的学生照片,上一次保存的训练数据。database/访问 mysql 的 JS 接口lib/一些通用的 JS 方法,比如爬虫接口,图片上传接口...opencv/搭建 nodejs 与 C++ 桥梁的源码与产生的链接库pretreat一些预处理接口,如人脸检测,图片灰化处理,样本数据的训练...routesexpress 的路由控制文件sslHTTPs 证书与密钥server.jsHTTP 服务入口index.js在调用server.js之前,获取前端数据,使得后端能够处理静态资源(image/css/...),为前后端公用一套代码提供解决方案。(一般在线上环境使用)provider.js创建子进程server.js,同时监听后端开发目录代码的改动,一旦改动便杀死上一个子进程,并且再次创建子进程server.js,可以实现后端代码的热更新。(一般在开发环境使用)
gp-njnu-photos-backend/
├── cpptest/
│ └── ...
├── test/
│ └── ...
├── data/
│ └── ...
├── database/
│ └── ...
├── lib/
│ └── ...
├── opencv/
│ └── ...
├── pretreat/
│ └── ...
├── routes/
│ └── ...
├── ssl/
│ └── ...
├── index.js
├── package.json
├── provider.js
└── server.js
过程(Learning Process)
学生照片下载
下载证件照就需要图片的 URL,在利用Python爬取学校网站上的证件照一文中,说到了教务处的学生证 URL 规则是 http://${hostname}/jwgl/photos/rx${year}/${studentno}.jpg ,hostname就是教务系统的主机地址,year就是入年份,studentno是学生学号,比如某学生学号是19140429,其中学号的3-4位表示入学年份,表示学生是 2014 年入学,那么他的学生证 URL 就是 http://223.2.10.123/jwgl/photos/rx2014/19140429;
知道了学生照的 URL 规则后,那么怎么得到各个学年入学的学生学号集合呢? 如果用穷举法,学号一共有 8 位,每位有 0-9 10 种可能,那么得到每一年的学生照片就需要 LOOP 10^8 次,这种级别的时间复杂度是不可接受的。于是通过查阅,搜索找到了 获取南师大学号,里面提到了获取学号的接口http://urp.njnu.edu.cn/authorizeUsers.portal?limit=100&term=191301,term 表示搜索关键字,可以是 1913/191301/... 将会返回学号中含有其字符串的数据,limit则是数据数最大限制,通过这个接口便可以得到学号集合
最后便是学生照片下载的代码书写了。 采用的是 Bash Script 书写,具有较强的易用性,不需要复杂的平台、环境依赖。第一版是使用 wget 指令进行下载,但是该指令在 windows/osx 需要额外安装,所以最后改成了 curl。
人脸识别理论学习
人脸识别实际包括构建人脸识别系统的一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份查找等。上一步已经完成了人脸的采集; 人脸定位也就是人脸的检测,在一张图片中,找出人脸的位置。通过一些特征提取的方法,如HOG特征,LBP特征,Haar特征,训练得到级联分类器,分类器对图像的任意位置和任意尺寸的部分(通常是正方形或长方形)进行分类,判定是或不是人脸。opencv源码中提供了一些常用的分类器(XML)。人脸识别预处理也就是对图像进行灰化,人脸检测,得到统一大小的人脸图片;然后便是识别了,对样本训练生成特征脸后,对于输入的人脸进行预处理后,得到其特征脸权重向量,计算向量距离,找到最小距离的样本人脸。
可以看到特征脸的生成是需要整个样本数据的,所以如果用户修改了样本数据,需要对全部样本重新训练,得到一组全新的特征脸。
opencv 环境安装
由于开发平台是 OSX ,而 OSX 有 Homebrew 神器
# 安装 Homebrew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
# 设置 Homebrew镜像代理,国内下载加速
cd "$(brew --repo)"
git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git
cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core"
git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git
brew update
echo 'export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles' >> ~/.bash_profile
source ~/.bash_profile
# 安装 opencv
brew tap homebrew/science
brew install opencvnode addons
node addons 是在 node 环境调用 C 系列接口的方法,已经有人用该方法写过 node-opencv,并在此基础上我还加上了 CircleLBP RectLBP ToThreeChannels PCA 算法,ToThreeChannels 是将 单通道(灰)或者 RGBA 通道变成 RGB 通道。
NAN_METHOD(Matrix::ToThreeChannels) {
Nan::HandleScope scope;
Matrix *self = Nan::ObjectWrap::Unwrap<Matrix>(info.This());
cv::Mat image;
if (self->mat.channels() == 3) {
image = self->mat;
} else if (self->mat.channels() == 1) {
cv::Mat myimg = self->mat;
cv::cvtColor(myimg, image, CV_GRAY2RGB);
} else if(self->mat.channels() == 4){
cv::Mat myimg = self->mat;
cv::cvtColor(myimg, image, CV_BGRA2RGB);
} else {
Nan::ThrowError("those channels are not supported");
}
self->mat = image;
info.GetReturnValue().Set(Nan::Null());
}图片预处理(人脸检测...)
通道统一 => 灰化 => 级联分类器检测人脸 => 人脸尺寸统一 => 保存
经过多次尝试后,对于学生证件照,最终比较得出,采用 LBP 级联分类器,窗口放大 1.95 倍左右效果较好。(测试数据在 backend/data/summary.json)
识别算法测试与确定
比较 opencv 中三种人脸识别算法,Eigen、Fisher、LBPH。数据在backend/cpptest/ 中
| 算法/时间(ms) | 实验1 | 实验2 | 实验3 | 实验4 | 实验5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 训练 | 预测 | 训练 | 预测 | 训练 | 预测 | 训练 | 预测 | 训练 | 预测 | |
| Eigen | 0.030648 | 0.010711 | 0.025524 | 0.011132 | 0.029332 | 0.007791 | 0.036231 | 0.020043 | 0.026972 | 0.005711 |
| Fisher | 0.040043 | 0.0089 | 0.039244 | 0.007145 | 0.033777 | 0.008276 | 0.043099 | 0.013723 | 0.039407 | 0.015095 |
| LBPH | 0.035812 | 0.071586 | 0.034822 | 0.075267 | 0.03204 | 0.067166 | 0.039263 | 0.075726 | 0.053047 | 0.074361 |
综合比较可以得出,效率 Eigen > Fisher > LBPH
所以采用Eigen(特征脸)算法
学生信息接口(爬虫)
该系统还需要获取到学生的个人信息,比如通过学号和密码验证是否正确等等。在同一届的同学中,已经有一位同学研究教务系统比较透彻了,而且做了一个查南师网站,所以我只需要爬取该网站的接口即可。
前端
该系统使用的是前后端分离的架构,页面的渲染交给客户端 JavaScript 来实现,后端只需要提供纯数据接口即可,让后端的工作更加纯粹。
对于页面路由的控制,使用的是 HTML5 的 History API ,交给 JavaScript 来控制,所以只要不进行页面的强制刷新(Ctrl/cmd + R),所有路径的跳转都是不会从服务器获取 HTML CSS 进行渲染,这就是单页 Web 应用的核心,这样一来,用户体验就更佳,服务器负载也更小,但对于浏览器要求更高了。
结合 React Web Component 和 CSS Module 思想,将前端页面细分为若干个组件,在上层 Page 中进行数据的传输,组件的组合,在 Page 上层还有一层 App,把一些全局通用的组件放这。
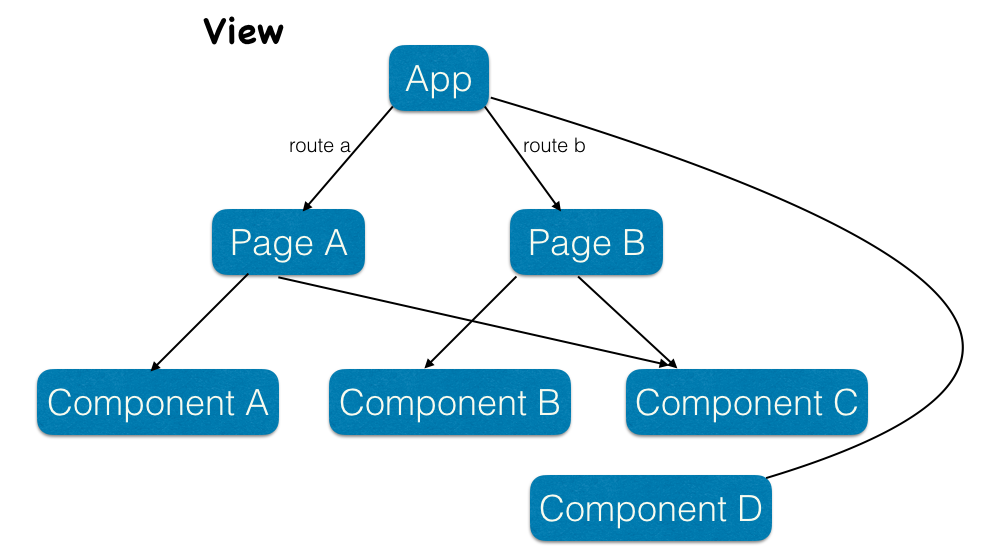
而且所有的数据控制都在 reducer 中,层次清晰,代码复用性高。
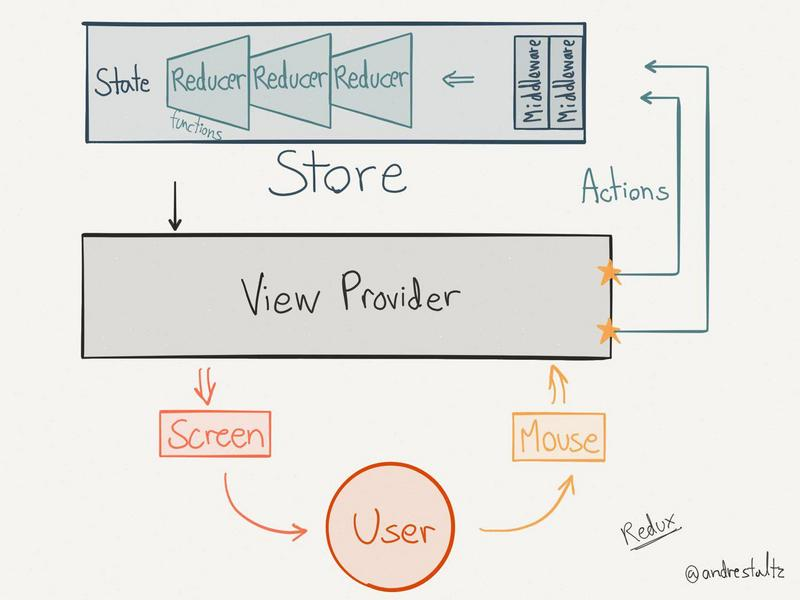
其中 workers/face.worker.js 文件是利用 Web Worker 起的另一个进程代码,主要做的是输入图片数据,输出人脸的位置大小,就是 JavaScript 版的人脸检测,之所以起另一个线程,是因为对于视频的人脸检测,对于实时性要求也比较高,检测也比较耗时,为了效率考虑使用了 Web Worker。
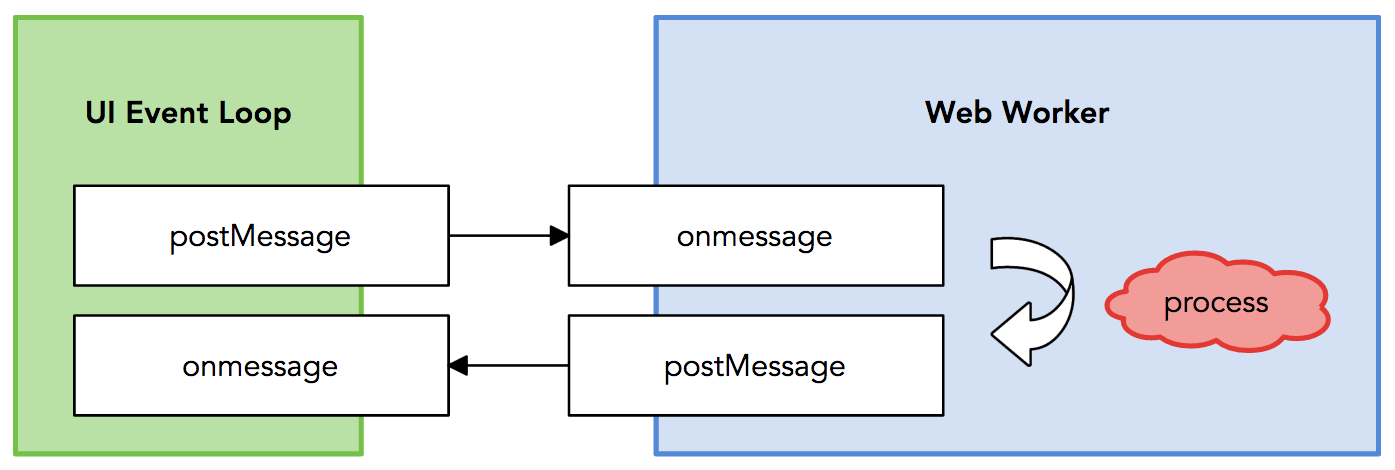
后端
由于视图的渲染都交给浏览器了,所以后端主要就是对于数据的逻辑处理了,比如样本录入,学生信息查询(爬虫),人脸识别(调用 opencv ),同时使用 mysql 数据库,存储样本录入的信息,表结构如下:
Table gp.`face_import`
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| stuid | varchar(20) | NO | | NULL | |
| time | datetime | NO | | NULL | |
| hash | varchar(20) | NO | PRI | NULL | |
| face_url | varchar(100) | NO | | NULL | |
+----------+--------------+------+-----+---------+-------+
hash 是每次上传样本的唯一 key 值,同时为了方便系统的部署迁移,没有将上传的样本数据存储在服务器中,而是存在 sm.ms 免费图床中,得到一个 face_url 字段,每次启动服务器之前都得进行样本的训练或者训练数据的读取;而且每次上传样本或者删除样本后,服务器都需要重新训练保存样本,重新生成一套特征脸。
并且在开启服务器的环境和纯粹的数据处理的环境对于数据库的处理是不一样的,在服务器环境,需要开启数据库连接池,每次都从中去取出连接进行数据操作;而纯粹的读取数据库,得到face_url进行人脸的预处理或训练,则只需要每次单独的 开启连接 => 读取数据 => 关闭连接 即可,否则程序会一直运行下去,因为数据库连接池没关闭。
同时,所有的前端数据接口都是 /api/* 规则,同时对于管理员的用户名和密码会进行 md5 不可逆编码然后再传输,防止被他人捕捉到。
同构渲染
上文说到所有的页面渲染都是交给 JavaScript 控制,服务器返回的 HTML结构如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>南师大学生签到系统</title>
<link rel="stylesheet" type="text/css" href="/pace.min.css">
<script type="text/javascript" src="/pace.min.js"></script>
<link href="/style.min.css?v=b5afb06f45be775a70081c1e320e6c40" rel="stylesheet"></head>
<body>
<div id="app"><!--HTML--></div>
<script type="text/javascript" src="/libs.min.js?v=8d589c56bcac1e2c17a7"></script>
<script type="text/javascript" src="/app.main.min.js?v=448dfe9c907942d09623"></script></body>
</html>其中任何数据都是没有的,只有 “第二时间” 通过 app.min.js 执行 JavaScript 进行渲染,所以对于用户短暂的 “第一时间” 感觉是不好的,什么都没有,也就是没有 “首屏渲染”,优化首屏渲染,就需要通过服务器返回带内容的 HTML。
由于前端使用的是 react,将 HTML 抽象成为 JSX,将 DOM操作 转化成状态的变化,重新渲染的思想,所以使得服务器端也能够解析react,redux 又将状态的更新操作抽离出来,使得服务器端可以更方便的控制状态从而进行渲染(当然,只有 nodejs 作为后端渲染层才可以做到),同时由于前端使用 Babel 编译前端代码,所以可以用新型语法糖,为了服务器端也能够识别,所以也需要 babel-register
import React from 'react';
import {renderToString} from 'react-dom/server'
import reactRouter, {match, RouterContext} from 'react-router'
import {Provider} from 'react-redux'
import MyRouter, {configureStore} from
// This is fired every time the server side receives a request
function handleRender(req, res, next) {
match({ routes: MyRouter, location: req.url }, function(error, redirectLocation, renderProps) {
if (error) {
res.status(500).send(error.stack);
} else if (redirectLocation) {
if(req.url.startsWith('/api') || fs.existsSync(path.join(fePath, url.parse(req.url).pathname)) ) {
next();
} else {
res.redirect(302, redirectLocation.pathname + redirectLocation.search);
}
} else if (renderProps) {
var store = configureStore();
// console.log(renderProps, store);
// we can invoke some async operation(eg. fetchAction or getDataFromDatabase)
// call store.dispatch(Action(data)) to update state.
store.dispatch(pushRoute(req.url))
if(req.url === '/about') {
store.dispatch(fetchRemoteMdText())
.then(data => {
res.renderStore(store, renderProps);
})
} else {
res.renderStore(store, renderProps);
}
} else {
res.status(404).send('Not found')
}
})
}
express.response.renderStore = function (store, renderProps) {
const html = renderToString(
<Provider store={store}>
<RouterContext {...renderProps} />
</Provider>
);
this.header('content-type', 'text/html; charset=utf-8')
this.send(renderFullPage('南师大刷脸签到系统', html, store.getState()))
}
const htmlPath = path.join(fePath, 'index.html');
var html = fs.readFileSync(htmlPath).toString();
function renderFullPage(title, partHtml, initialState) {
// <!--HTML-->
var allHtml = html;
if(initialState) {
allHtml = allHtml.replace(/\/\*\s*?INITIAL_STATE\s*?\*\//, `window.__INITIAL_STATE__=${JSON.stringify(initialState)}`)
}
if(title) {
allHtml = allHtml.replace(/<title>[\s\S]*?<\/title>/, `<title>${title}</title>`);
}
return allHtml.replace(/<!--\s*?HTML\s*?-->/, partHtml);
}
同时让浏览器得到初始状态,window.__INITIAL_STATE__=${JSON.stringify(initialState)},把初始状态window.__INITIAL_STATE__ 传给客户端
const isBrowser = (() => !(typeof process === 'object' && typeof process.versions === 'object' && typeof process.versions.node !== 'undefined'))();
var _initState = isBrowser && window.__INITIAL_STATE__ || initState
const store = configureStore(
_initState
)
以上,便可以实现同构渲染,既保证了 SPA 的用户体验,首屏渲染,而且解决了SEO(搜索引擎优化)的问题。
部署
开发的差不多后,找朋友要了个 ubuntu 的服务器,首先麻烦的就是环境的迁移了,由于源码都部署在 GitHub 上,所以直接 git clone 就可以得到了(原始证照和预处理后的证照、训练的 yaml 数据都没提交至 GitHub,所以代码库还是挺小的)。
然后 Ubuntu 上安装 opencv,Ubuntu 上可没有 Homebrew 神奇,所以只能下载源码包,自己进行编译连接,生成动态链接库
安装好 node + npm + nvm,node 版本 ≥7.0,以及 mysql,导入 gp.sql
再在服务器执行 npm install(安装项目依赖包,各个目录下都有自己独立的依赖包,前端目录则不必安装,因为只需要其产生的代码) => 下载脚本 => 预处理脚本 => 训练样本脚本 => 启动服务器
nginx + https
但是服务器启动后,外网还是不能直接访问,需要通过 nginx 反向代理,同时解析域名至服务器 IP,为了浏览器安全可以打开摄像头,还需要开启 HTTPs 协议,我使用的是腾讯云免费的一年证书,然后 nginx 配置后即可。
SEO
为了增强站点的曝光率,就需要做 SEO 了,添加 robots.txt,站点地图,同时在前端页面加入不可见的 a 标签,利于网页爬虫爬取其他链接
PC Desktop
为了方便师生使用,还使用 nativefier 将站点打包成 PC Desktop,其实就是将站点 URL 和 Chrome 内核组合成一个 Application
代码解析(Code Analysis)
下面对某些代码进行剖析
获取ID集合
// gp-image-download/lib/get-all-id.js
// language: javascript
// env: node
// usage: (cd gp-image-download && node get-all-id.js)
const URL = "http://urp.njnu.edu.cn/authorizeUsers.portal"
const STU_FILE = "data/students.json"
// 需要在浏览器先登录,得到已登录的 Cookie
const COOKIE = "njnuurpnew=ac16c83bd341d8ba0c3f2f092378; JSESSIONID=0001gcUXI0GWjdQg_ptI6NGAFaf:-5B0INP"
/* 请求 URL,写入 COOKIE,得到数据个数 recordCount */
async function getLimit() {
try {
const x = await get({
...url.parse(URL),
headers: { cookie: COOKIE }
})
// console.log('xx', x)
const json = JSON.parse(x)
return json.recordCount
} catch (ex) {
console.error(ex);
}
}
/* 请求 URL,写入 COOKIE,得到全部学生集合 */
async function getStuIds(limit) {
try {
const x = await get({
...url.parse(URL+"?limit="+limit),
headers: { cookie: COOKIE }
})
const json = JSON.parse(x)
return json.principals.filter(x=>{
let metier = x.metier.trim();
return metier=='本专科生'
})
} catch (ex) {
console.error(ex);
}
}
/* 由于全部学生数据量比较大,所以写入文件,下次读取文件即可 */
async function writeStudents() {
const limit = await getLimit()
const stus = await getStuIds(limit)
console.log('writing "%s"', STU_FILE)
fs.writeFileSync(STU_FILE, JSON.stringify(stus, null, 4))
assignStuIds()
}
/* 读取全部学生数据,按照入学年份区分,得到以\r\n分割的学号集合文件 */
function assignStuIds() {
const stus = JSON.parse(fs.readFileSync(STU_FILE))
let all = stus.reduce((p, n) => {
//19130126
if(/^[\d]{8}$/.test(n.id)) {
let num = n.id.substr(2, 2);
let year = "20"+num;
if(year>YEAR || isNaN(num)) return p
p[year] = p[year] || ''
p[year] += n.id+'\r\n'
}
return p
}, {})
Object.keys(all).forEach(k =>{
let v = all[k];
console.log('writing "%s"', "data/student-ids-"+k+".txt")
fs.writeFile("data/student-ids-"+k+".txt", v.replace(/\r\n$/, ''), ()=>{})
})
}下载图片脚本
#!/bin/bash
// gp-image-download/download.sh
// language: bash script
// env: bash
// usage: (cd gp-image-download && ./download.sh 2013)
base="http://223.2.10.123/jwgl/photos/rx"
year="2013"
# 没有 images/ 文件夹则新建,健壮性
if [ ! -d images ]; then
echo mkdir images
mkdir images
fi
cd images
# 将year赋值为第一个参数,默认为 2013
if [ ! -z "$1" ]; then
year=$1
fi
echo year=$year
if [ ! -d $year ]; then
echo mkdir $year
mkdir $year
fi
cd $year
# 读取上一步获取的学号集合,放入arr
while IFS=$'\r\n' read var; do
arr+=($var)
done < ../../data/student-ids-$year.txt
# 将下载好的图片,按照 学年/班级/图片 放置
assign_file() {
Name=${1##*/}
Classno=${Name:0:6}
if [ ! -d $Classno ]; then
mkdir $Classno
fi
mv $Name "$Classno"/
}
# 下载图片
# params: $1 url; $2 filename
down() {
URL=$1
Name=$2
data=`curl --fail --silent $URL`
# "$data" 不能少 因为data中可能包含[]
if [ ! -z "$data" ]; then
curl --fail --silent $URL > $Name
echo "SUCCESS! $URL"
fi
}
# 遍历arr,下载
for id in ${arr[@]}; do
if [ ! -z $id ]; then
Name=${id//$\s/}.jpg
down "$base""$year"/$Name $Name
fi
done
# 下载结束后,重新放置文件
arr=(*)
for x in ${arr[@]}; do
assign_file $x
donenpm 脚本
// gp-njnu-photos-backend/package.json
// usage: (cd gp-njnu-photos-backend && npm run $scriptName)
# 图片预处理
# detect face, then gray, save
# eg. $ npm run grayface 2013 191301
# $ npm run grayface 2013
# $ npm run grayface
# npm run grayface year classno
# 样本训练并写入文件。
# after read grayface images, then train and save it
# eg. $ node pretreat/train_save.js -f --args 2013
# $ node pretreat/train_save.js -f --args 2013 191301
# -f:重新训练,不论是否已存在训练数据
# --args year classno 训练哪一年哪一班级的图片
"grayface": "node pretreat/gray_face.js",
"train:force": "node pretreat/train_save.js -f",
"train:smart": "node pretreat/train_save.js",
"dev:w": "cross-env NODE_STATUS=run, NODE_ENV=dev node .",
"dev": "cross-env NODE_STATUS=run, NODE_ENV=dev node index.js",
"start": "cross-env NODE_STATUS=run, NODE_ENV=prod node index.js",
"retrain": "npm run grayface && npm run train:force",
"retrain:dev": "npm run grayface 2013 191301 && node pretreat/train_save.js -f --args 2013 191301",开发环境(热部署)脚本
// gp-njnu-photos-backend/provider.js
// language: javascript
// env: node
// usage: (cd gp-njnu-photos-backend && npm run dev:w)
var cp = require('child_process')
var p = require('path')
var fs = require('fs')
const isDir = (filepath) => fs.statSync(filepath).isDirectory()
/* 去除掉 非文件夹,node_modules文件夹,`.`开头的文件夹 */
const children = fs.readdirSync(__dirname).filter(n=>n!='node_modules' && !n.startsWith('.') && isDir(p.join(__dirname, n)));
[__dirname].concat(children).forEach(dir => fs.watch(dir, watchHandle))
/* 监听到文件被修改则触发 */
function watchHandle (type, filename) {
// 无视不是js文件和点开头命名的文件
if(filename.startsWith('.') || !filename.endsWith(".js")) {
return;
}
console.log(type, filename);
// 杀死内存中的服务器进程
serverProcess.kill('SIGINT');
serverProcess = runServer();
}
var serverProcess = runServer();
/* fork index.js 进程 */
function runServer() {
return cp.fork('./index.js', process.argv, {stdio: [0, 1, 2, 'ipc']})
}服务器自动更新代码
- 服务器端
// gp-njnu-photos-backend/routes/control.js
/* 访问 /api/ctrl/pull 服务器执行 git pull,从 github 更新代码 */
ctrl.all('/pull', (req, res) => {
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive'
});
var ls = require('child_process').spawn('git', ['pull', 'origin', 'master'])
ls.stdout.on('data', (data) => {
data = data.toString()
console.log(data)
res.write(`${data}`);
});
ls.stderr.on('data', (data) => {
data = data.toString()
console.log(data)
res.write(`${data}`);
});
ls.on('close', (code) => {
console.log(`child process exited with code ${code}`)
res.end(`child process exited with code ${code}`);
});
})- 本机(开发机)
// path.sh
#!/bin/bash
msg="from bash"
if [ -n "$1" ]; then
msg=$1
# 重新 build 前端代码
(cd gp-njnu-photos-app && npm run build)
fi
git add .
git commit -m "$msg"
git push
# 如果push成功(exitcode=0),则访问远端 /api/ctrl/pull,从而服务器也更新了代码
if [ $? = 0 ]; then
curl https://face.moyuyc.xyz/api/ctrl/pull
fiDesktop打包脚本
// package.json
// usage: npm run script-name
"app:mac64": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -a x64 -p mac --insecure -n 古南师大刷脸签到 https://face.moyuyc.xyz/ -i desktop/logos/logo.icns --disable-dev-tools --disable-context-menu desktop",
"app:mac32": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -a ia32 -p mac --insecure -n 古南师大刷脸签到 \"https://face.moyuyc.xyz/\" -i desktop/logos/logo.icns --disable-dev-tools --disable-context-menu desktop",
"app:mac": "npm run app:mac32 & npm run app:mac64",
"app:win": "npm run app:win32 & npm run app:win64",
"app:win32": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -p win32 -a x64 --insecure -n 古南师大刷脸签到 \"https://face.moyuyc.xyz/\" -i desktop/logos/logo.png --disable-dev-tools --disable-context-menu desktop",
"app:win64": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -p win32 -a ia32 --insecure -n 古南师大刷脸签到 \"https://face.moyuyc.xyz/\" -i desktop/logos/logo.png --disable-dev-tools --disable-context-menu desktop",一键搭建环境脚本
// start.sh
// language: bash script
// env: bash
// usage: ./start.sh
#!/bin/bash
echoerr() { echo "$@" 1>&2; }
command_exists () { type "$1" &> /dev/null; }
command_exists_exit() {
if ! command_exists "$1" ; then
echoerr "${1} command not exists"
exit
fi
}
# 必须的指令检查 git npm node mysql
command_exists_exit git
command_exists_exit npm
command_exists_exit node
command_exists_exit mysql
# 是否已经 clone 过,已经 clone 过,则更新代码,否则 clone
if [ -d face-njnu ]; then
(cd face-njnu && git pull)
else
git clone https://github.com/moyuyc/graduation-project.git face-njnu
fi
# 要求输入下载同学的入学年份
read -p "which year do you want to download? (2013) [2013/n] " REPLY
if [[ $REPLY =~ ^[\s]*$ ]]; then
YEAR=2013
echo "Downloading... Year=$YEAR"
(cd face-njnu/gp-image-download && ./download.sh $YEAR)
elif [[ $REPLY =~ ^[nN]$ ]]; then
echo "Skipped Download Images"
else
YEAR=$REPLY
echo "Downloading... Year=$YEAR"
(cd face-njnu/gp-image-download && ./download.sh $YEAR)
fi
echo "mysql data importing"
# 是否需要导入 sql 数据到 mysql
read -p "Are you sure import sql data? [y/n]" REPLY
if [[ $REPLY =~ ^[yY]$ ]]; then
# 输入 mysql 用户名,默认 root
read -p "Username(root): " REPLY
if [[ $REPLY =~ ^[\s]*$ ]]; then
USER=root
else
USER=$REPLY
fi
mysql -u $USER -p gp < face-njnu/gp.sql
fi
# 是否需要安装 opencv
read -p "Are you sure install opencv? [y/n]" REPLY
if [[ $REPLY =~ ^[yY]$ ]]; then
if command_exists apt-get; then
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
fi
if command_exists wget ; then
wget -O ~/opencv.zip https://github.com/opencv/opencv/archive/2.4.13.1.zip
unzip opencv.zip
mv ~/opencv-2.4.13.1 ~/opencv
else
# git clone https://github.com/Itseez/opencv_contrib.git ~/opencv_contrib
git clone https://github.com/opencv/opencv.git ~/opencv
(cd ~/opencv && git checkout 2.4)
fi
(cd ~/opencv && rm -rf release && mkdir release \
&& cd release && \ # ~/opencv_contrib/modules:
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local .. \
&& make \
&& sudo make install)
fi
if command_exists node-gyp ;
npm install node-gyp -g --registry=https://registry.npm.taobao.org
fi
# 安装项目依赖,并且启动
cd face-njnu
npm install --registry=https://registry.npm.taobao.org
cd gp-njnu-photos-backend
npm install --registry=https://registry.npm.taobao.org
(cd opencv && npm run install )
npm run retrain && npm run start系统模块(System Module)
系统截图(System Screenshot)
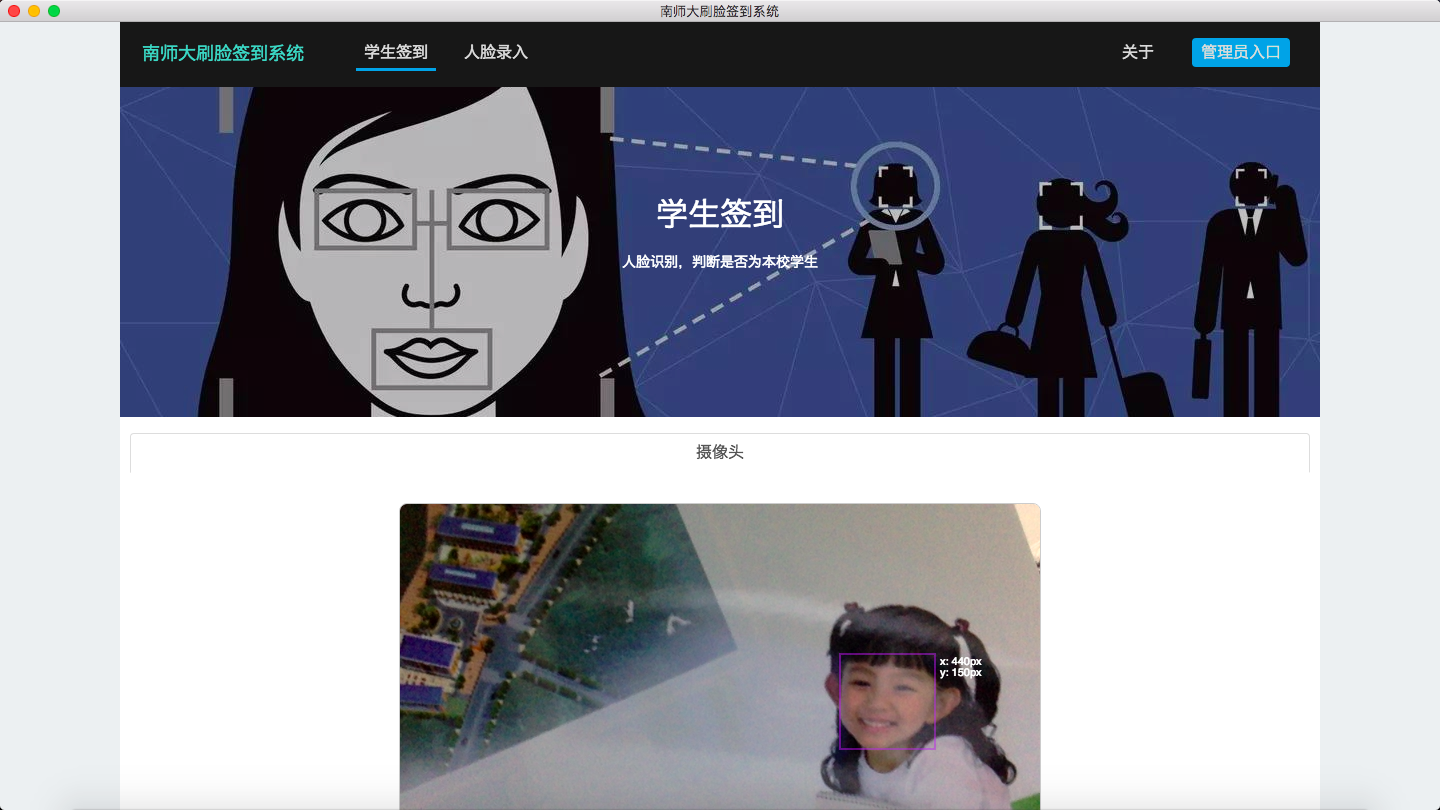
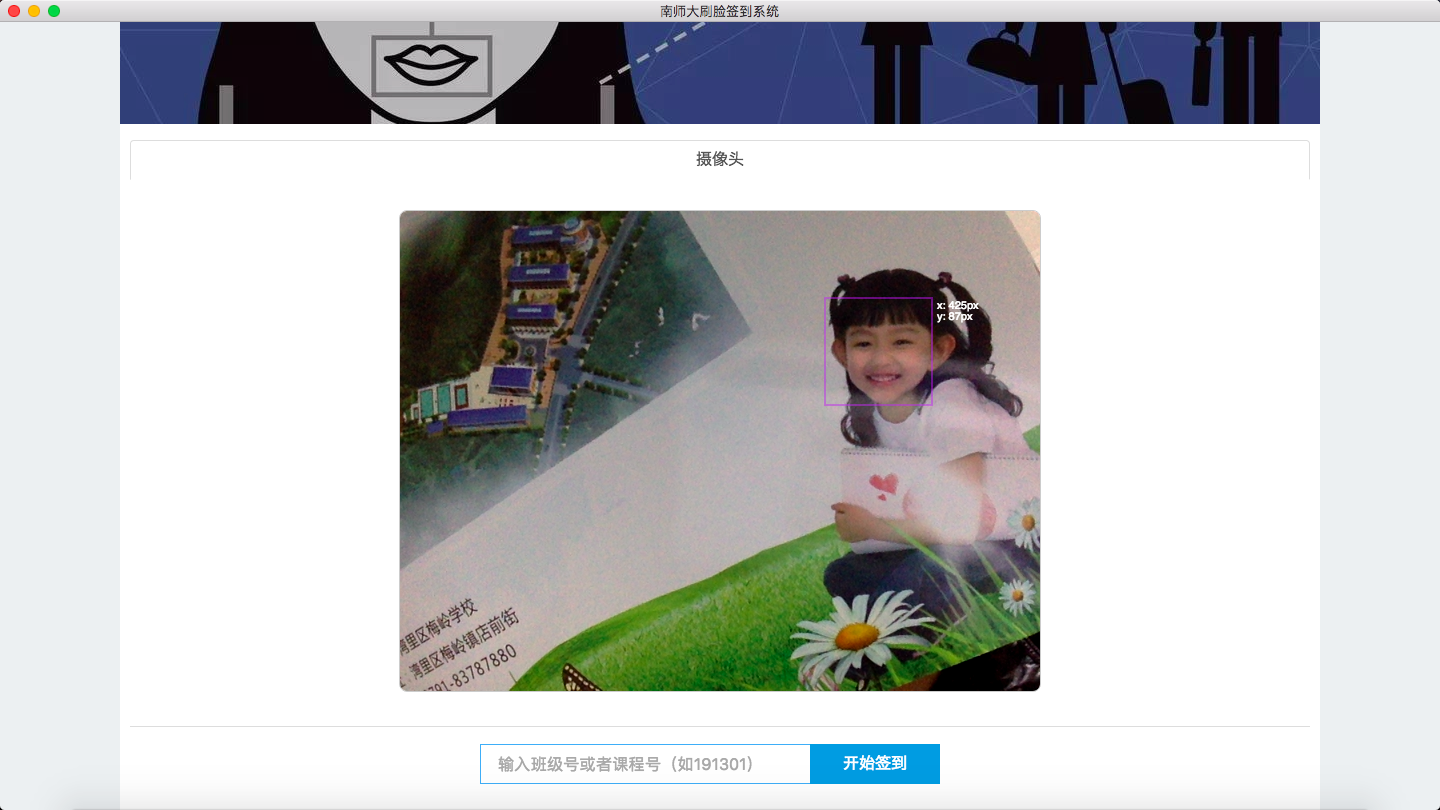
学生签到
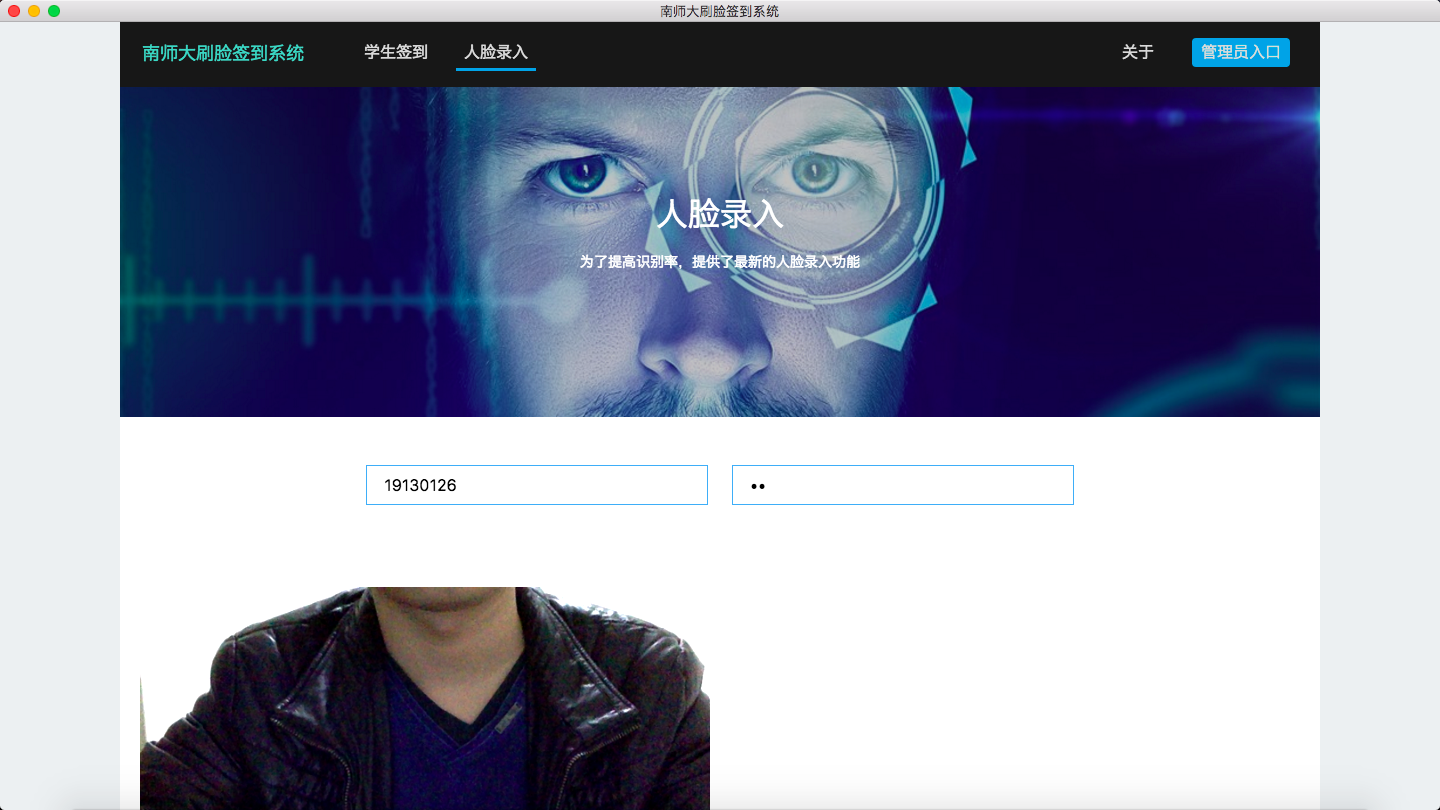
人脸录入
关于
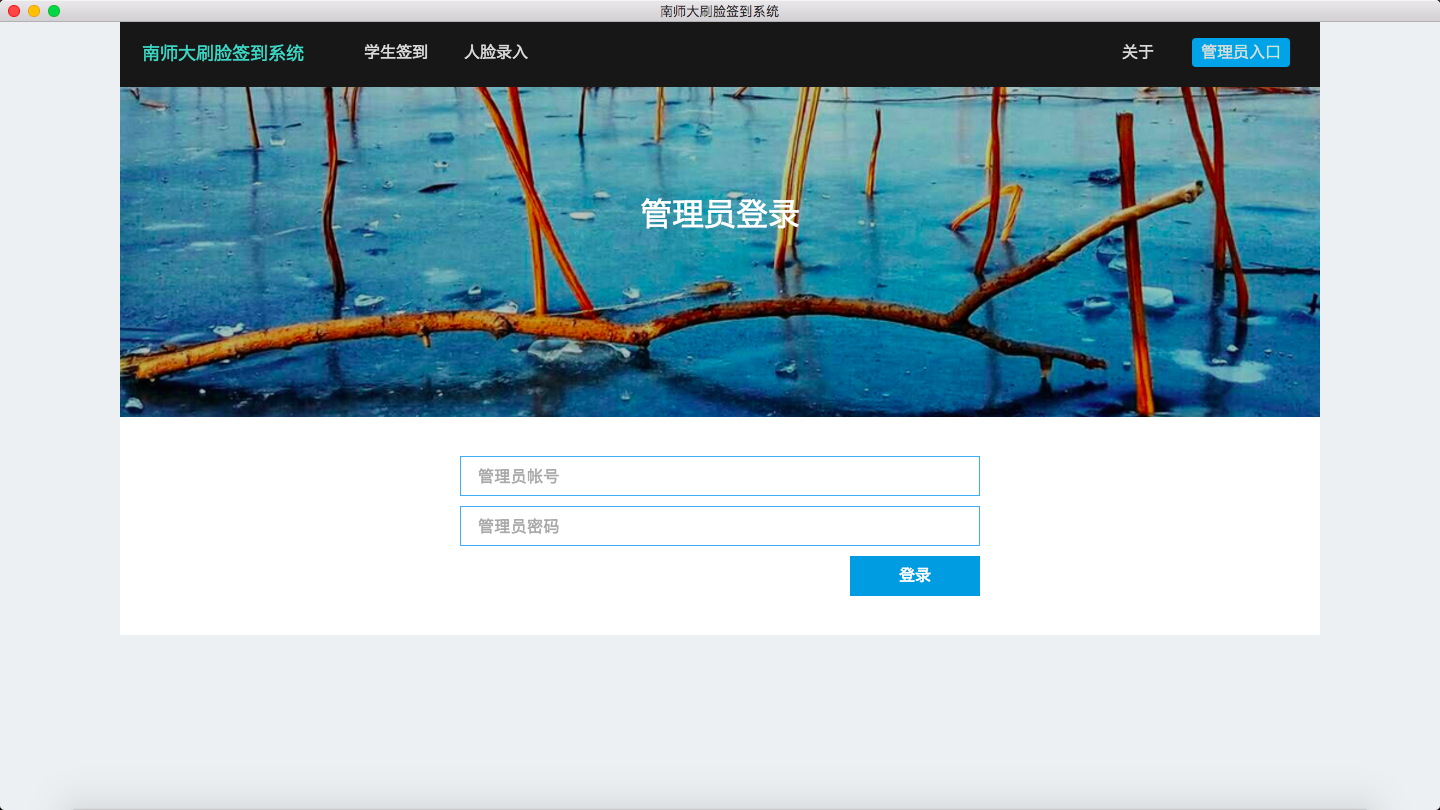
管理员登录
管理员界面
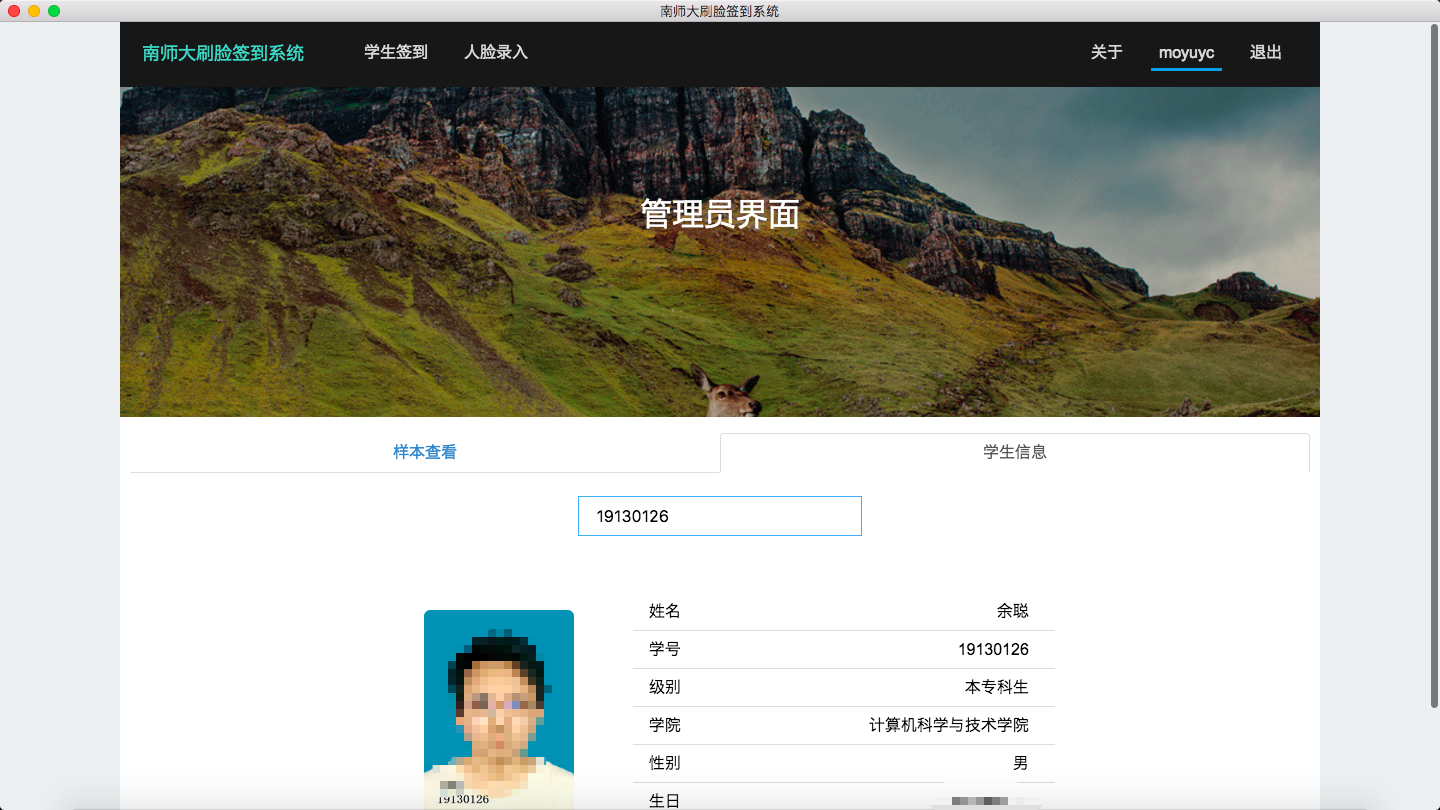
总结(Sum Up)
学习并且使用了一套的 webpack+react+redux+router,以及同构渲染;同时巩固了一些 C 系列语言知识,尝试了 node 与 C/C++ “通信”的方式,入门学习了 opencv 以及人脸图像处理相关知识;尝试了站点的发布,与 HTTPs 的升级。对 前端/Nodejs/Web 体系认识更加深刻,对 unix 指令环境更加熟悉。