
毕业论文初稿
绪论
研究背景和意义
相信有不少人有过丢失邀请函、替换或借用身份牌参会的经历。可对于部分高端会议或国家级会展活动来说,确认参会人员的身份十分关键,传统的签到模式无疑给了盗用身份参会者钻空子的机会。但是随着人脸识别技术水平的不断提升,其应用领域越来越广,效率也越来越高。使得人脸识别能够很有效的解决签到问题。
国内外研究现状
国内目前主要是三种力量,一个是清华大学的苏光大教授,他是中国的人脸识别之父。第二个是中科院的自动化所的李教授,他早年在微软的亚洲研究院当中获得了非常高的成就,后来到了中科院的自动化所,专攻人脸识别。第三支就是香港中文大学的汤晓鸥教授的团队,每年会进行学术界的比赛,他是高记录的保持者。 国外著名的研究机构有美国MIT的Media lab,AI lab,CMU的Human-Computer Interface Institute,Microsoft Research,英国的Department of Engineering in University of Cambridge等。 当前人脸识别技术所存在的主要问题 1. 人脸图像的获取过程中的不确定性(如光的方向,以及光的强度等)。 2. 人脸模式的多样性(如胡须,眼镜,发型等)。 3. 人脸塑性变形的不确定性(如表情等)。 4. 所涉及的领域知识的综合性
本课题研究内容
人脸识别问题可以定义成 : 输入 (查询) 场景中 的静止图像或者视频 ,使用人脸数据库识别或验证 场景中的一个人或者多个人[12] . 基于静止图像的人 脸识别通常是指输入 (查询) 一幅静止的图像 ,使用 人脸数据库进行识别或验证图像中的人脸. 而基于 视频的人脸识别是指输入 (查询) 一段视频 ,使用人 脸数据库进行识别或验证视频中的人脸. 如不考虑 视频的时间连续信息 ,问题也可以变成采用多幅图 像(时间上不一定连续) 作为输入(查询) 进行识别或 验证. 对静止图像中人脸的定位可参见文献[2] , 对视频中人脸的定位和分割可参见文献[13]
本文内容组织结构
本文主要讲述刷脸签到系统的设计与实现,全文共分为五章。
- 第一章 绪论,介绍了研究背景、国内外研究现状和本文研究内容。
- 第二章 涉及技术,介绍了该系统所涉及的所有领域的技术介绍。
- 第三章 设计与实现,解释了该系统的设计结构与部分主要算法的流程。
- 第四章 总结与感谢,总结了本文的主要工作内容和个人感悟,以及一些感谢语。
涉及技术介绍
系统技术栈
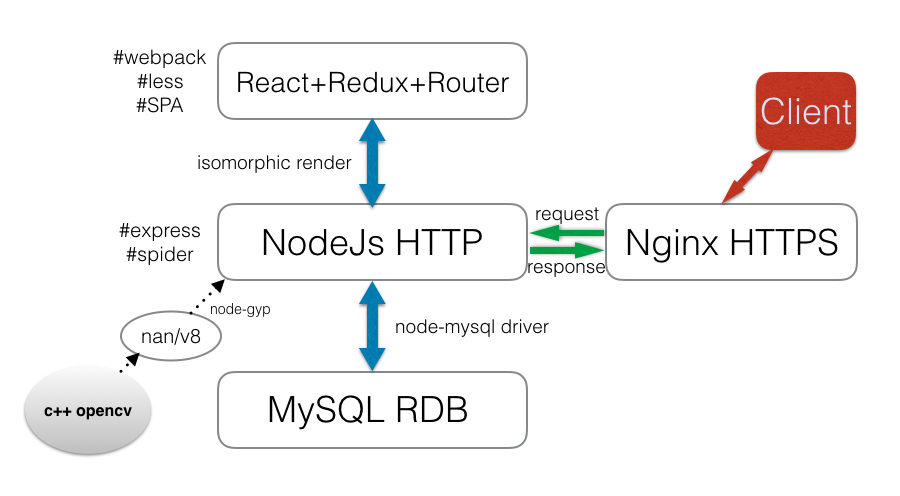
前端涉及技术
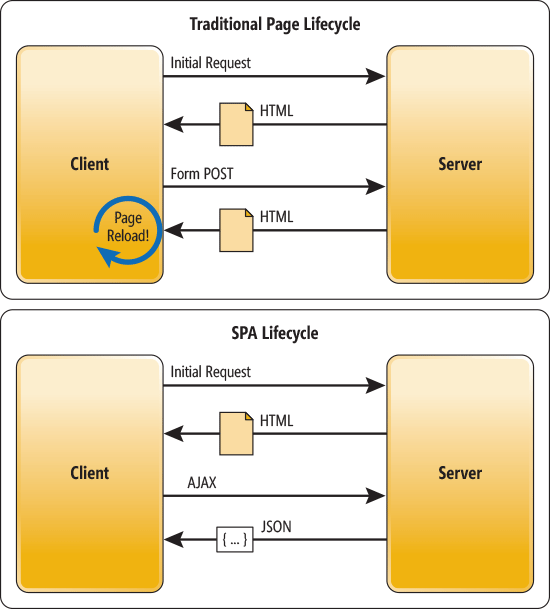
- 单页Web应用(single page web application,SPA),就是只有一张Web页面的应用。单页应用程序 (SPA) 是加载单个HTML 页面并在用户与应用程序交互时动态更新该页面的Web应用程序。 浏览器一开始会加载必需的HTML、CSS和JavaScript,所有的操作都在这张页面上完成,都由 JavaScript 来控制。因此,对单页应用来说模块化的开发和设计显得相当重要。
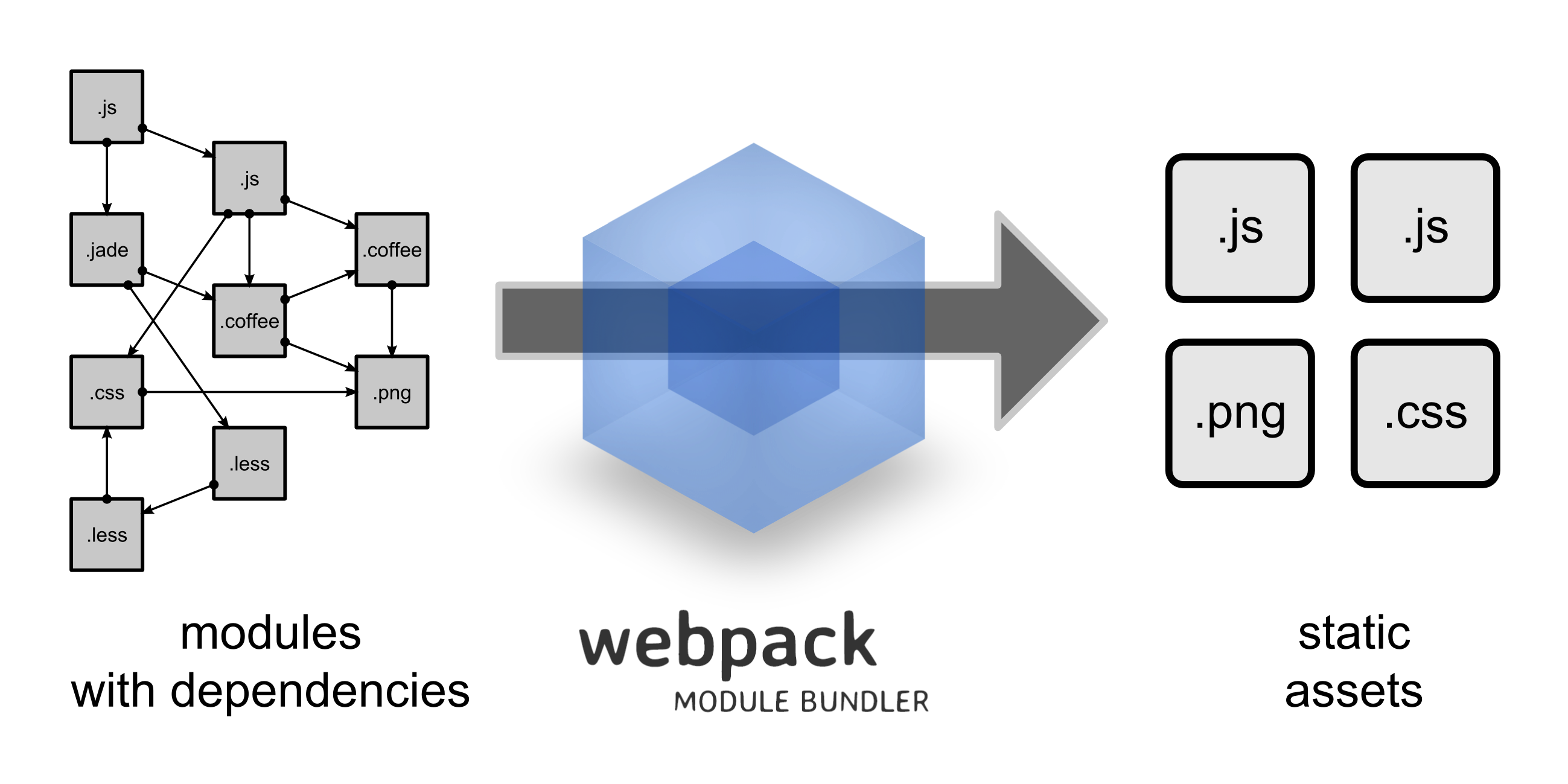
- 使用主流 Webpack 构建,进行前端模块自动化管理。
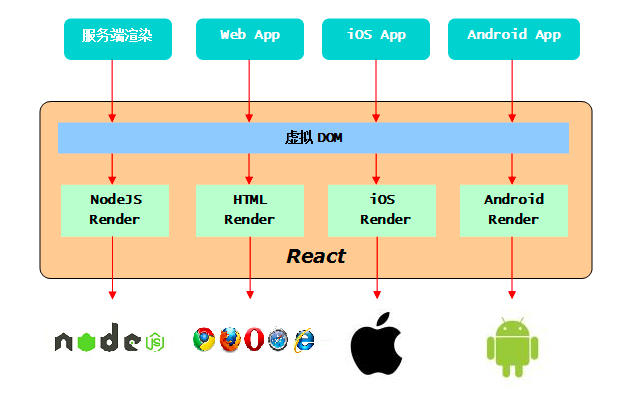
- 使用Facebook提出的 React 进行作为 View, 将 HTML DOM 进行上层抽象,提出 Virtual DOM 概念,一套理念,实现了Server render, Web UI, mobile UI 的统一。 Learn Once, Write Anywhere
- Redux,随着 JavaScript 单页应用开发日趋复杂,JavaScript 需要管理比任何时候都要多的 state (状态),state 在什么时候,由于什么原因,如何变化已然不受控制。 当系统变得错综复杂的时候,想重现问题或者添加新功能就会变得举步维艰, Redux则是为了解决该痛点而产生。
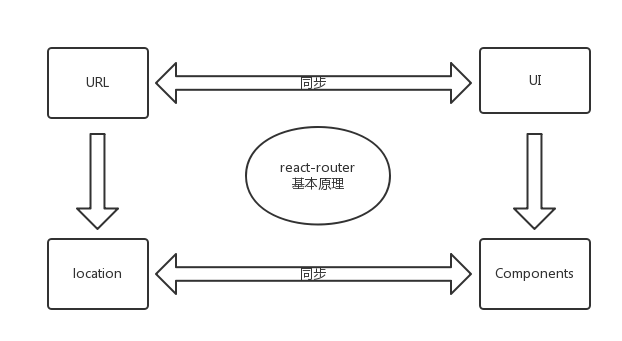
- React Router 是一个基于 React 之上的强大路由库,它可以让你向应用中快速地添加视图和数据流,既保证了单页应用的畅快,同时保持页面与 URL 间的同步。
- *Babel => 使用 JavaScript 实现的编译器,正如官网所说的那样 Use next generation JavaScript, today. ,可以利用 Babel 书写最新的 JavasScript 语法标准,如 ECMAScript 6 ,搭配 Webpack 使用更佳。
- *ECMAScript6 => 2015 年提出的JavaScript标准,目标是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。ECMAScript和JavaScript的关系是,前者是后者的规格,后者是前者的一种实现。ES 6 具有一系列简明的语法糖,更佳的书写体验。但为了保证浏览器, Node 环境兼容性,往往配合 Babel 书写。
- *less => 一种 CSS 预处理语言,增加了诸如变量、混合(mixin)、函数等功能,让 CSS 更易维护、方便制作主题、扩充。
- 使用 HTML5 的 getUserMedia 方法,调用计算机音频视频等硬件设备。为了安全问题,Chrome 只能在本地地址上调用该方法,外网地址则只能在通过证书检测的 HTTPS 服务中调用。
后端涉及技术
- 采用 nodeJs 作为后端,采用 JavaScript 脚本语言开发。 nodeJs 具有异步事件驱动、非阻塞(non-blocking)IO 特性,采用 Google 的 V8 引擎来执行代码。
- Node.js以单线程运行,使用非阻塞I/O调用,这样既可以支持数以万计的并发连接,又不会因多线程本身的特点而带来麻烦。众多请求只使用单线程的设计意味着可以用于创建高并发应用程序。Node.js应用程序的设计目标是任何需要操作I/O的函数都使用回调函数。 这种设计的缺点是,如果不使用cluster、StrongLoop Process Manager或pm2等模块,Node.js就难以处理多核或多线程等情况。
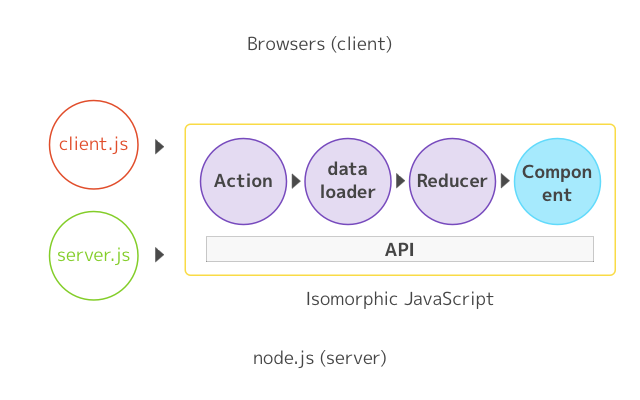
- isomorphic render(同构渲染)=> 指的是前后端使用同一份代码。前端通过 Webpack 实现 CommonJs 的模块规范(Node亦是 CommonJs )+ React 提出的 JSX ,使得 NodeJs 通过解析请求的 URL,适配 react-router 中的前端路由规则,得到 routing Props,还可以 dispatch(action) 同步或异步(一般是 isomorphic-fetch ),又或是直接读取数据,从而更新 store ,最后 nodeJs 通过 store 中的 state 渲染 JSX ,产生静态的 HTML,从而实现了前后端的同构渲染。
- nodeJs C++ Addons,nodeJs 就是使用C++语言实现的,图像处理最强大的库 opencv 便是用 C++ 实现的,这就不得不需要 nodeJs 与 C++ 之前通信,通过 nodeJs 调用 opencv 的方法,node-opencv 便是利用 nan (解决平台间兼容性问题,将异步事件驱动封装)与 v8 (javascript 对应的数据类型与 C++映射) ,通过 node-gyp 工具,将 C++ 打包成 一个动态链接库 *.node,通过 require 即可调用。
- node-mysql ,由于 NodeJs 具有 non-blocking IO 与异步事件驱动的特性,所以很适合于 IO 密集型高并发业务,而访问数据库正是常用的 IO 操作。
- NPM(全称Node Package Manager,即node包管理器),是Node预设的,通过国内 taobao 镜像可以加快下载速度。
- Express(Node.js Web 应用程序框架),很方便的定义 restful api.
- Spider,网络爬虫,通过转发客户端的 HTTP 或 HTTPs 请求,得到远程服务器的响应数据,然后再一次转发至客户端中,也就是代理的意思 关于南师大的一些 API ,已经有前人用 Python 写过了,爬取教务系统数据,然后我只需要爬取对应的网站即可。
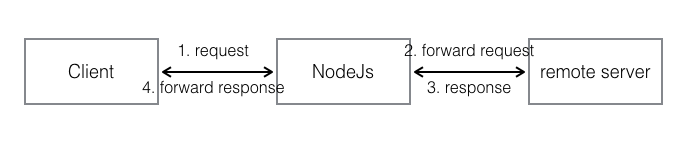
- nginx,使用 C++ 实现的 Web 服务器,通过简单的配置就可以反向代理至正确的端口和应用层协议。
- 由于浏览器安全性的考虑,对于外网地址使用摄像头需要在安全的HTTPs协议下,因此需要付费或免费地得到认可的证书,通过 nginx 配置,反向代理至 Node 进程即可。
其他涉及技术
- git 是用于 Linux 内核开发的版本控制工具。与 CVS、Subversion 一类的集中式版本控制工具不同,它采用了分布式版本库的作法,不需要服务器端软件,就可以运作版本控制,使得源代码的发布和交流极其方便。 git 的速度很快,这对于诸如 Linux 内核这样的大项目来说自然很重要。git 最为出色的是它的合并追踪(merge tracing)能力。
- GitHub 是一个通过 Git 进行版本控制的软件源代码托管服务,是全球最大的代码存放网站和开源社区。
- 特征脸(Eigenface)是指用于机器视觉领域中的人脸识别问题的一组特征向量。这些特征向量是从高维矢量空间的人脸图像的协方差矩阵计算而来。一组特征脸 可以通过在一大组描述不同人脸的图像上进行主成分分析(PCA)获得。任意一张人脸图像都可以被认为是这些标准脸的组合。另外,由于人脸是通过一系列向量(每个特征脸一个比例值)而不是数字图像进行保存,可以节省很多存储空间。
- 主成分分析(Principal components analysis,PCA)是一种分析、简化数据集的技术。主成分分析经常用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。
- OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV用C++语言编写,它的主要接口也是C++语言。
系统设计与实现
系统模块
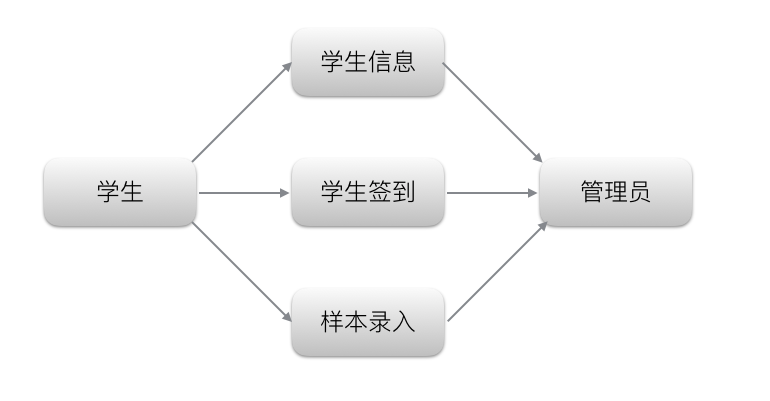
文件结构
顶层文件结构如下
Graduation-Project/
├── desktop/
├── gp-image-download/
├── gp-njnu-photos-app/
└── gp-njnu-photos-backend/
desktop/ 中放的是将站点打包成 PC Desktop 的 Logo,logo.icns 用在 osx 系统中,logo.png 则用于 linux 与 windows 系统中,打包成的 PC Desktop 默认也是放在该文件夹下。
desktop/
└── logos/
├── logo.icns
├── logo.ico
└── logo.png
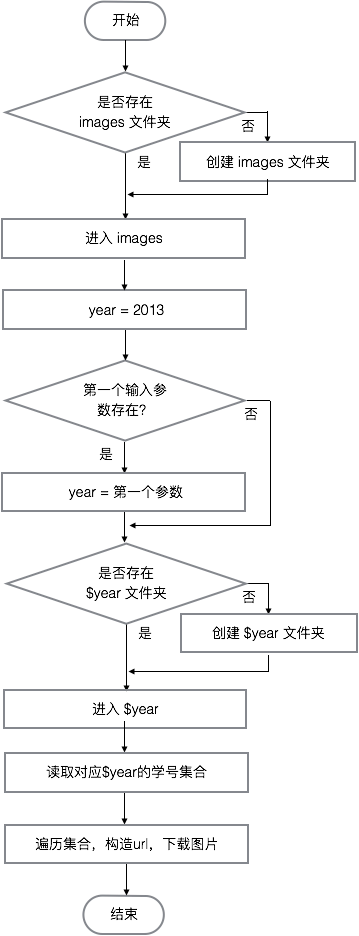
gp-image-download/ 文件夹里面放的是将教务系统的学生图片下载至该文件夹中,其中的 data/ 文件夹放的是各年入学的学生的学号(部分学号不正确),数据是 get-all-id.js 脚本得到,具体工作细节在后面会说到。保证获取到各年的学生学号集后,通过 download.sh Bash 脚本即可进行下载;下载的图片放在 images/ 中。
gp-image-download/
├── data/
│ └── ...
├── download.sh
├── get-all-id.js
├── images/
│ └── ...
└── lib/
└── get-all-id.js
gp-njnu-photos-app/ 放的是前端代码,app/ 是开发用的源码,build/ 是用 Webpack 打包的压缩后的发布资源,包括 css/js/html/image...
gp-njnu-photos-app/
├── app/
│ └── ...
├── build/
│ └── ...
├── index.js
├── package.json
├── webpack-assets.json
└── webpack.config.js
gp-njnu-photos-backend/ 放的是后端的全部代码。
gp-njnu-photos-backend/
├── cpptest/
│ └── ...
├── test/
│ └── ...
├── data/
│ └── ...
├── database/
│ └── ...
├── lib/
│ └── ...
├── opencv/
│ └── ...
├── pretreat/
│ └── ...
├── routes/
│ └── ...
├── ssl/
│ └── ...
├── index.js
├── package.json
├── provider.js
└── server.js
cpptest/c++ opencv 的一些测试test/nodejs 调用 opencv 接口的例子data/放些人脸 xml 模板数据,服务器运行时生成的缓存数据,预处理后的学生照片,上一次保存的训练数据。database/访问 mysql 的 JS 接口lib/一些通用的 JS 方法,比如爬虫接口,图片上传接口...opencv/搭建 nodejs 与 C++ 桥梁的源码与产生的链接库pretreat一些预处理接口,如人脸检测,图片灰化处理,样本数据的训练...routesexpress 的路由控制文件sslHTTPs 证书与密钥server.jsHTTP 服务入口index.js在调用server.js之前,获取前端数据,使得后端能够处理静态资源(image/css/...),为前后端公用一套代码提供解决方案。(一般在线上环境使用)provider.js创建子进程server.js,同时监听后端开发目录代码的改动,一旦改动便杀死上一个子进程,并且再次创建子进程server.js,可以实现后端代码的热更新。(一般在开发环境使用)
实现
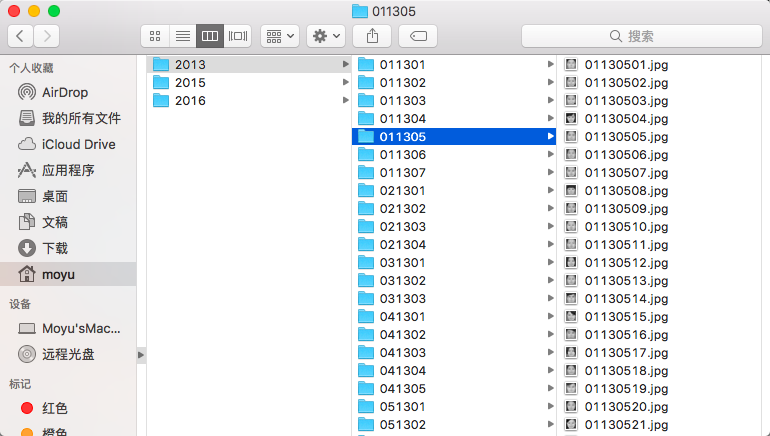
学生照片下载
下载证件照就需要图片的 URL,在利用Python爬取学校网站上的证件照一文中,说到了教务处的学生证 URL 规则是 http://${hostname}/jwgl/photos/rx${year}/${studentno}.jpg ,hostname就是教务系统的主机地址,year就是入年份,studentno是学生学号,比如某学生学号是19140429,其中学号的3-4位表示入学年份,表示学生是 2014 年入学,那么他的学生证 URL 就是 http://223.2.10.123/jwgl/photos/rx2014/19140429;
知道了学生照的 URL 规则后,那么怎么得到各个学年入学的学生学号集合呢? 如果用穷举法,学号一共有 8 位,每位有 0-9 10 种可能,那么得到每一年的学生照片就需要 LOOP 10^8 次,这种级别的时间复杂度是不可接受的。于是通过查阅,搜索找到了 获取南师大学号,里面提到了获取学号的接口http://urp.njnu.edu.cn/authorizeUsers.portal?limit=100&term=191301,term 表示搜索关键字,可以是 1913/191301/... 将会返回学号中含有其字符串的数据,limit则是数据数最大限制,通过这个接口便可以得到学号集合
最后便是学生照片下载的代码书写了。 采用的是 Bash Script 书写,具有较强的易用性,不需要复杂的平台、环境依赖。第一版是使用 wget 指令进行下载,但是该指令在 windows/osx 需要额外安装,所以最后改成了 curl。
人脸识别理论学习
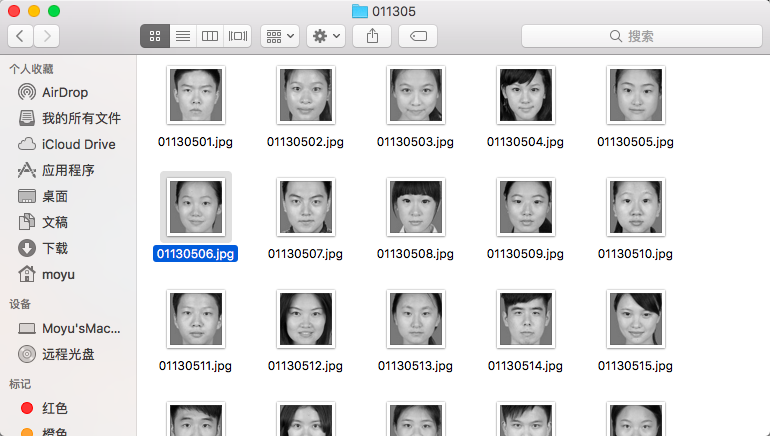
人脸识别实际包括构建人脸识别系统的一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份查找等。上一步已经完成了人脸的采集; 人脸定位也就是人脸的检测,在一张图片中,找出人脸的位置。通过一些特征提取的方法,如HOG特征,LBP特征,Haar特征,训练得到级联分类器,分类器对图像的任意位置和任意尺寸的部分(通常是正方形或长方形)进行分类,判定是或不是人脸。opencv源码中提供了一些常用的分类器(XML)。人脸识别预处理也就是对图像进行灰化,人脸检测,得到统一大小的人脸图片;然后便是识别了,对样本训练生成特征脸后,对于输入的人脸进行预处理后,得到其特征脸权重向量,计算向量距离,找到最小距离的样本人脸。
可以看到特征脸的生成是需要整个样本数据的,所以如果用户修改了样本数据,需要对全部样本重新训练,得到一组全新的特征脸。
opencv 环境安装
由于开发平台是 OSX ,而 OSX 有 Homebrew 神器
# 安装 Homebrew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
# 设置 Homebrew镜像代理,国内下载加速
cd "$(brew --repo)"
git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git
cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core"
git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git
brew update
echo 'export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles' >> ~/.bash_profile
source ~/.bash_profile
# 安装 opencv
brew tap homebrew/science
brew install opencvnode C/C++扩展
node C/C++扩展是在 node 环境调用 C 系列接口的方法。

node-opencv,并在此基础上我还加上了 CircleLBP RectLBP ToThreeChannels PCA 算法,ToThreeChannels 是将 单通道(灰)或者 RGBA 通道变成 RGB 通道。下图给出的是通用的 ConvertChannels 的算法流程图,主要可以转化图像的通道数,输入参数 n: int 通道数 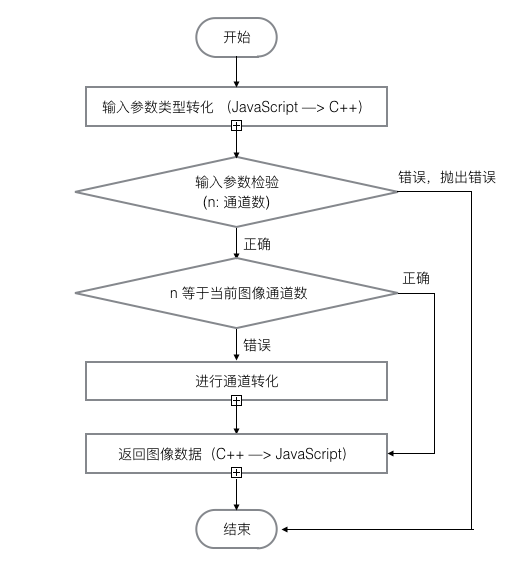
图片预处理(人脸检测...)
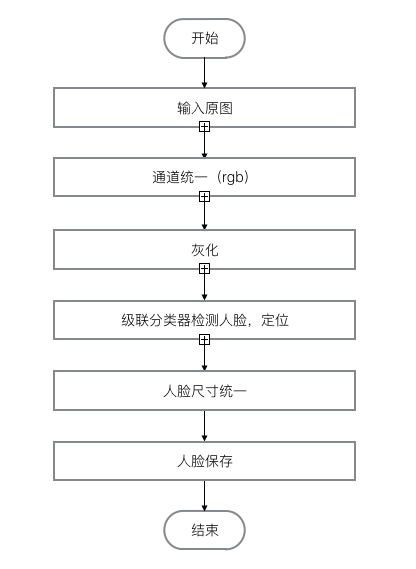
经过多次尝试后,对于学生证件照,最终比较得出,采用 LBP 级联分类器,窗口放大 1.95 倍左右效果较好。(测试数据在 backend/data/summary.json)
识别算法测试与确定
比较 opencv 中三种人脸识别算法,Eigen、Fisher、LBPH。数据在backend/cpptest/ 中
| 算法/时间(ms) | 实验1 | 实验2 | 实验3 | |||
|---|---|---|---|---|---|---|
| 训练 | 预测 | 训练 | 预测 | 训练 | 预测 | |
| Eigen | 0.030648 | 0.010711 | 0.025524 | 0.011132 | 0.029332 | 0.007791 |
| Fisher | 0.040043 | 0.0089 | 0.039244 | 0.007145 | 0.033777 | 0.008276 |
| LBPH | 0.035812 | 0.071586 | 0.034822 | 0.075267 | 0.03204 | 0.067166 |
综合比较可以得出,效率 Eigen > Fisher > LBPH
所以采用Eigen(特征脸)算法
学生信息接口(爬虫)
该系统还需要获取到学生的个人信息,比如通过学号和密码验证是否正确等等。在同一届的同学中,已经有一位同学研究教务系统比较透彻了,而且做了一个查南师网站,并且该网站不需要输入验证码进行身份验证,所以我只需要爬取该网站的接口即可。
前端
该系统使用的是前后端分离的架构,页面的渲染交给客户端 JavaScript 来实现,后端只需要提供纯数据接口即可,让后端的工作更加纯粹。
对于页面路由的控制,使用的是 HTML5 的 History API ,交给 JavaScript 来控制,所以只要不进行页面的强制刷新(Ctrl/cmd + R),所有路径的跳转都是不会从服务器获取 HTML CSS 进行渲染,这就是单页 Web 应用的核心,这样一来,用户体验就更佳,服务器负载也更小,但对于浏览器要求更高了。
结合 React Web Component 和 CSS Module 思想,将前端页面细分为若干个组件,在上层 Page 中进行数据的传输,组件的组合,在 Page 上层还有一层 App,把一些全局通用的组件放这。
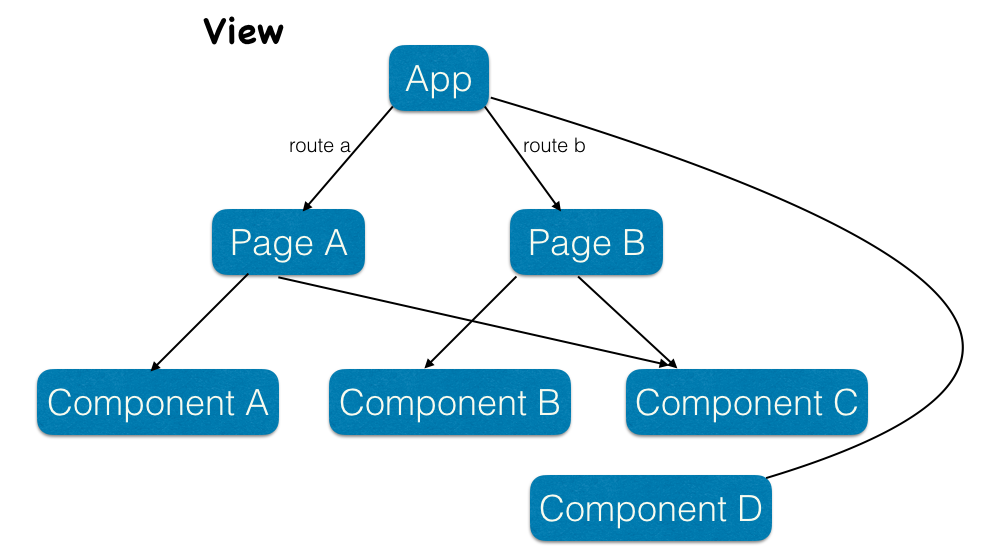
而且所有的数据控制都在 reducer 中,层次清晰,代码复用性高。
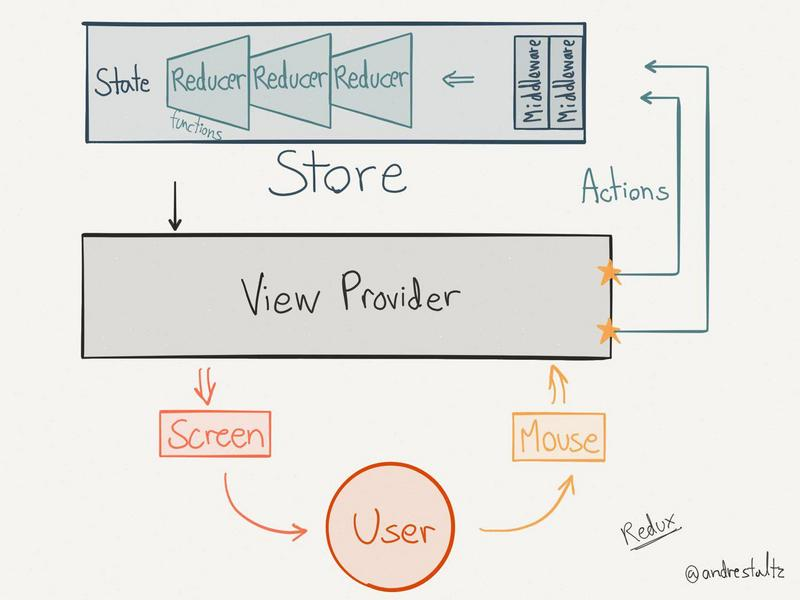
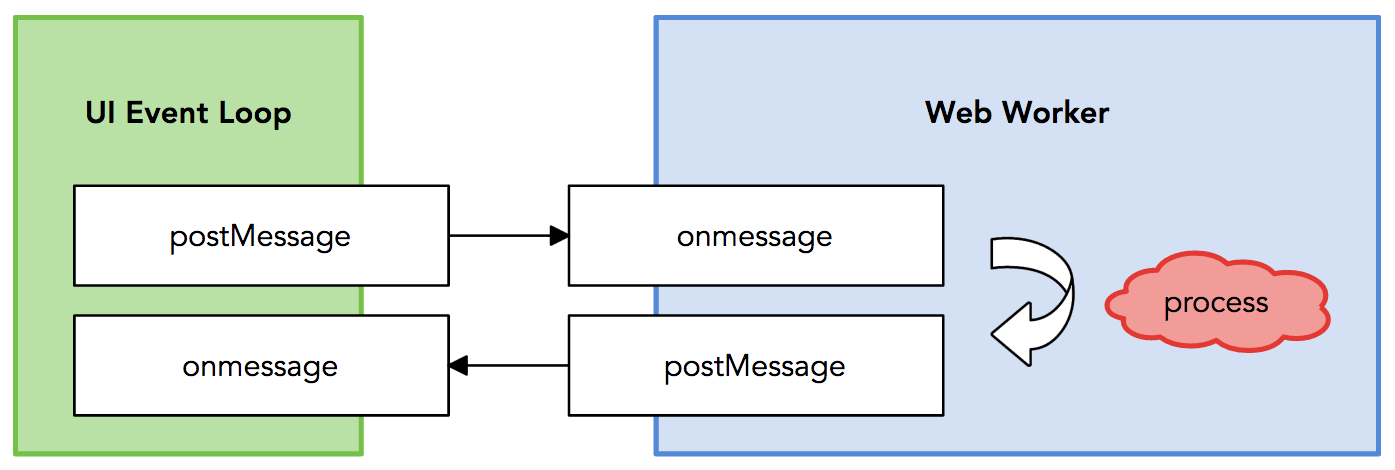
其中 workers/face.worker.js 文件是利用 Web Worker 起的另一个进程代码,主要做的是输入图片数据,输出人脸的位置大小,就是 JavaScript 版的人脸检测,之所以起另一个线程,是因为对于视频的人脸检测,对于实时性要求也比较高,检测也比较耗时,为了效率考虑使用了 Web Worker。
后端
由于视图的渲染都交给浏览器了,所以后端主要就是对于数据的逻辑处理了,比如样本录入,学生信息查询(爬虫),人脸识别(调用 opencv ),同时使用 mysql 数据库,存储样本录入的信息,表结构如下:
Table gp.`face_import`
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| stuid | varchar(20) | NO | | NULL | |
| time | datetime | NO | | NULL | |
| hash | varchar(20) | NO | PRI | NULL | |
| face_url | varchar(100) | NO | | NULL | |
+----------+--------------+------+-----+---------+-------+
hash 是每次上传样本的唯一 key 值,同时为了方便系统的部署迁移,没有将上传的样本数据存储在服务器中,而是存在 sm.ms 免费图床中,得到一个 face_url 字段,每次启动服务器之前都得进行样本的训练或者训练数据的读取;而且每次上传样本或者删除样本后,服务器都需要重新训练保存样本,重新生成一套特征脸。
并且在开启服务器的环境和纯粹的数据处理的环境对于数据库的处理是不一样的,在服务器环境,需要开启数据库连接池,每次都从中去取出连接进行数据操作;而纯粹的读取数据库,得到face_url进行人脸的预处理或训练,则只需要每次单独的 开启连接 => 读取数据 => 关闭连接 即可,否则程序会一直运行下去,因为数据库连接池没关闭。
同时,所有的前端数据接口都是 /api/* 规则,同时对于管理员的用户名和密码会进行 md5 不可逆编码然后再传输,防止被他人捕捉到。
同构渲染
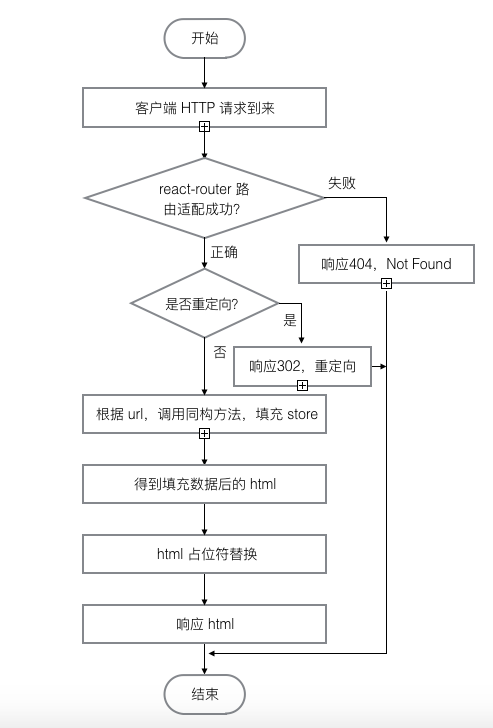
上文说到所有的页面渲染都是交给 JavaScript 控制,服务器返回的 HTML 结构如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>南师大学生签到系统</title>
<link rel="stylesheet" type="text/css" href="/pace.min.css">
<script type="text/javascript" src="/pace.min.js"></script>
<link href="/style.min.css?v=b5afb06f45be775a70081c1e320e6c40" rel="stylesheet">
</head>
<body>
<div id="app"><!--HTML--></div>
<script type="text/javascript" src="/libs.min.js?v=8d589c56bcac1e2c17a7"></script>
<script type="text/javascript" src="/app.main.min.js?v=448dfe9c907942d09623"></script>
</body>
</html>其中任何数据都是没有的,只有 “第二时间” 通过 app.min.js 执行 JavaScript 进行渲染,所以对于用户短暂的 “第一时间” 感觉是不好的,什么都没有,也就是没有 “首屏渲染”,优化首屏渲染,就需要通过服务器返回带内容的 HTML。
由于前端使用的是 react,将 HTML 抽象成为 JSX,将 DOM 操作 转化成状态的变化,重新渲染的思想,所以使得服务器端也能够解析react,redux 又将状态的更新操作抽离出来,使得服务器端可以更方便的控制状态从而进行渲染(当然,只有 nodejs 作为后端渲染层才可以做到),同时由于前端使用 Babel 编译前端代码,所以可以用新型语法糖,为了服务器端也能够识别,所以也需要 babel-register
同时让浏览器得到初始状态,window.__INITIAL_STATE__=${JSON.stringify(initialState)},把初始状态window.__INITIAL_STATE__ 传给客户端
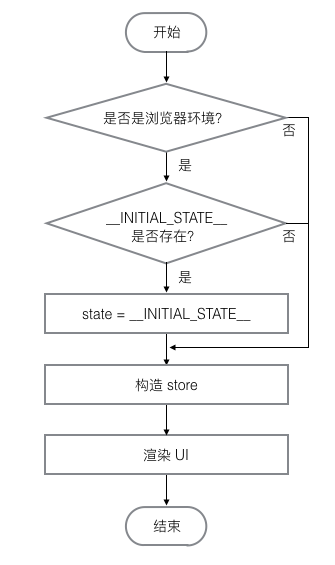
以上,便可以实现同构渲染,既保证了 SPA 的用户体验,首屏渲染,而且解决了SEO(搜索引擎优化)的问题。
部署
开发的差不多后,找朋友要了个 ubuntu 的服务器,首先麻烦的就是环境的迁移了,由于源码都部署在 GitHub 上,所以直接 git clone 就可以得到了(原始证照和预处理后的证照、训练的 yaml 数据都没提交至 GitHub,所以代码库还是挺小的)。
然后 Ubuntu 上安装 opencv,Ubuntu 上可没有 Homebrew 神奇,所以只能下载源码包,自己进行编译连接,生成动态链接库
安装好 node + npm + nvm,node 版本 ≥7.0,以及 mysql,导入 gp.sql
再在服务器执行 npm install(安装项目依赖包,各个目录下都有自己独立的依赖包,前端目录则不必安装,因为只需要其产生的代码) => 下载脚本 => 预处理脚本 => 训练样本脚本 => 启动服务器
nginx + https
但是服务器启动后,外网还是不能直接访问,需要通过 nginx 反向代理,同时解析域名至服务器 IP,为了浏览器安全可以打开摄像头,还需要开启 HTTPs 协议,我使用的是腾讯云免费的一年证书,然后 nginx 配置后即可。
SEO
前文已经介绍到,虽然该 Web 站点是 SPA,但是由于同构渲染的技术,单独通过 URL 也是可以直接获取到带内容的数据的,所以网络爬虫可以很方便的爬取该站点,为 SEO 做下基础。 为了增强站点的曝光率,就需要做 SEO 了,添加 robots.txt,站点地图,同时在前端页面加入不可见的 a 标签,利于网页爬虫爬取其他链接
PC Desktop
为了方便师生使用,还使用 nativefier 将站点打包成 PC Desktop,其实就是将站点 URL 和 Chrome 内核组合成一个 Application。nativefier 是基于 Electron 的, Electron 将 Chrome 内核和 nodejs 融合在一起,所以你可以使用前端技术(HTML/CSS/JavaScript)和 nodejs api 及其第三方 node 包,利用 chrome 和 nodejs 的跨平台性,基于 Electron 的 App 也是可以跨平台的(Mac, Windows, Linux)。
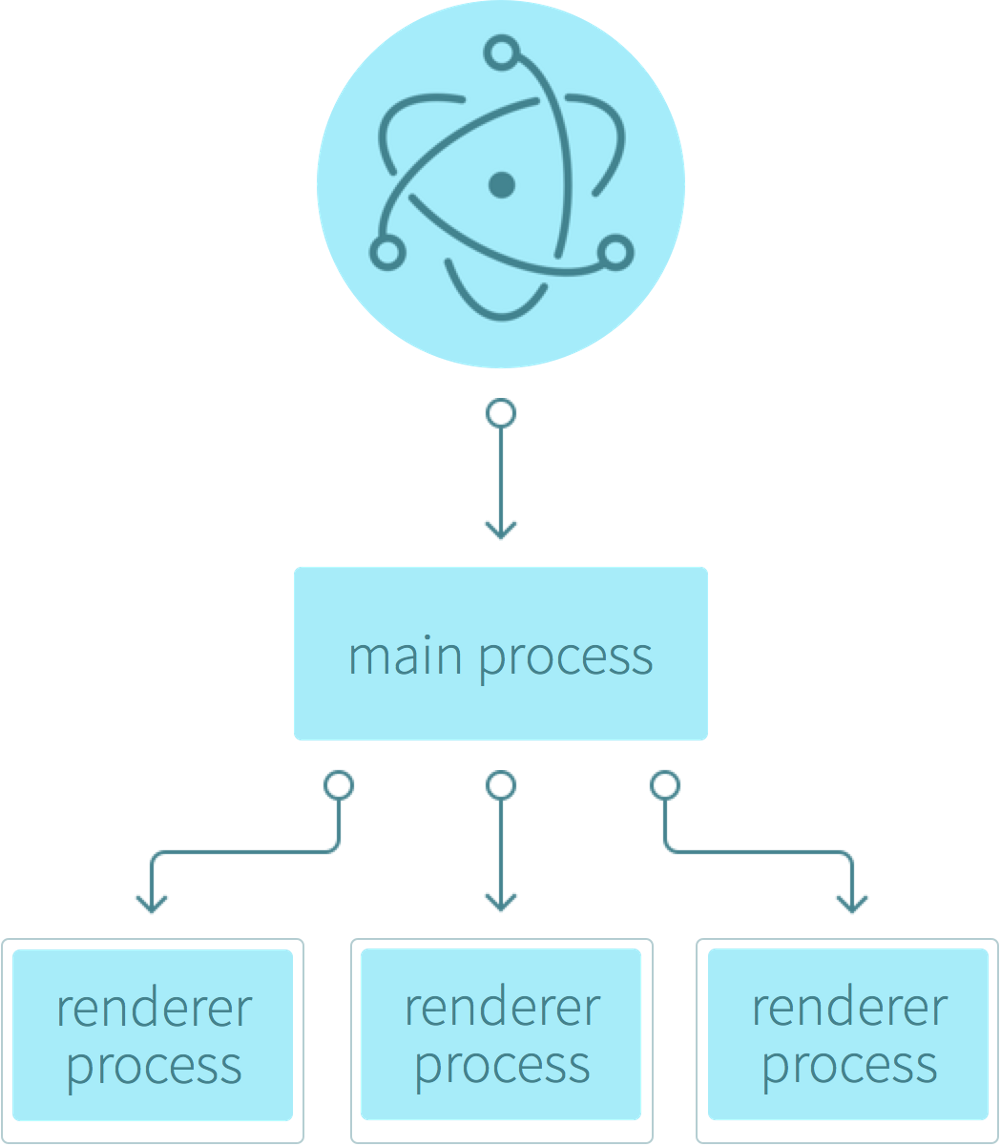
当你启动了一个 Electron 应用,就有一个主进程(main process )被创建了。这条进程将负责创建出应用的 GUI(也就是应用的窗口),并处理用户与这个 GUI 之间的交互。
但直接启动 main.js 是无法显示应用窗口的,在 main.js 中通过调用BrowserWindow模块才能将使用应用窗口。然后每个浏览器窗口将执行它们各自的渲染器进程( renderer process )。渲染器进程将会处理一个真正的 web 页面(HTML + CSS + JavaScript),将页面渲染到窗口中。
主要代码流程示意
下面对某些代码进行剖析
获取ID集合
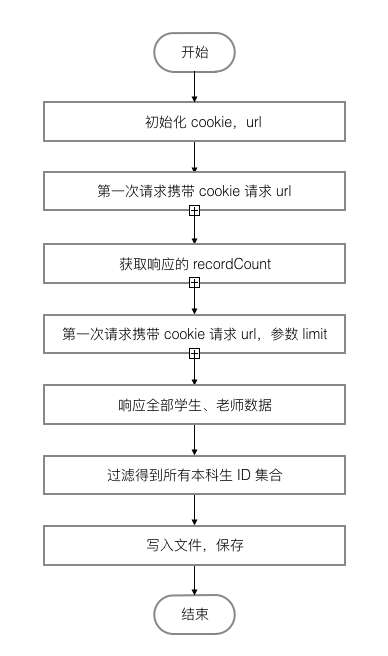
文件:gp-image-download/lib/get-all-id.js
语言:JavaScript
环境:Nodejs
使用:(cd gp-image-download && node get-all-id.js)
主要通过手动登录,获取到未过期的已登录 Cookie,然后携带 Cookie,访问 http://urp.njnu.edu.cn/authorizeUsers.portal ...
下载图片脚本
文件:gp-image-download/download.sh
语言:bash script
环境:bash
使用:(cd gp-image-download && ./download.sh 2013)
npm 命令
文件:gp-njnu-photos-backend/package.json
使用:(cd gp-njnu-photos-backend && npm run $scriptName)
# 图片预处理
# detect face, then gray, save
# eg. $ npm run grayface 2013 191301
# $ npm run grayface 2013
# $ npm run grayface
# npm run grayface year classno
# 样本训练并写入文件。
# after read grayface images, then train and save it
# eg. $ node pretreat/train_save.js -f --args 2013
# $ node pretreat/train_save.js -f --args 2013 191301
# -f:重新训练,不论是否已存在训练数据
# --args year classno 训练哪一年哪一班级的图片
"grayface": "node pretreat/gray_face.js",
"train:force": "node pretreat/train_save.js -f",
"train:smart": "node pretreat/train_save.js",
"dev:w": "cross-env NODE_STATUS=run, NODE_ENV=dev node .",
"dev": "cross-env NODE_STATUS=run, NODE_ENV=dev node index.js",
"start": "cross-env NODE_STATUS=run, NODE_ENV=prod node index.js",
"retrain": "npm run grayface && npm run train:force",
"retrain:dev": "npm run grayface 2013 191301 && node pretreat/train_save.js -f --args 2013 191301",开发环境(热部署)脚本
文件:gp-njnu-photos-backend/provider.js
语言:JavaScript
环境:Nodejs
使用:(cd gp-njnu-photos-backend && npm run dev:w)
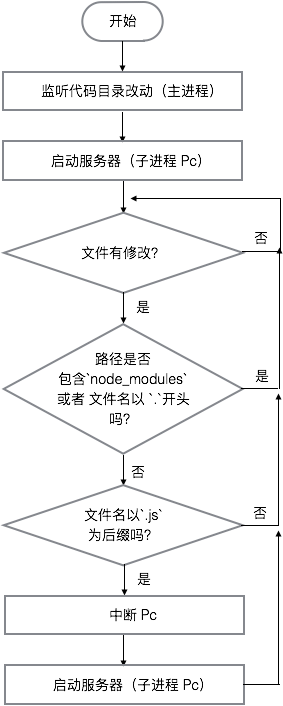
服务器自动更新代码
- 服务器端
文件:gp-njnu-photos-backend/routes/control.js
语言:JavaScript
环境:Nodejs
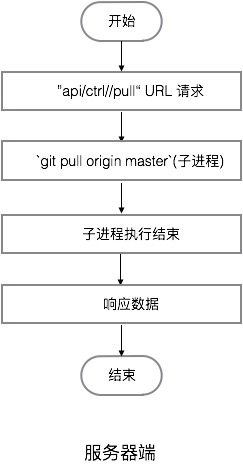
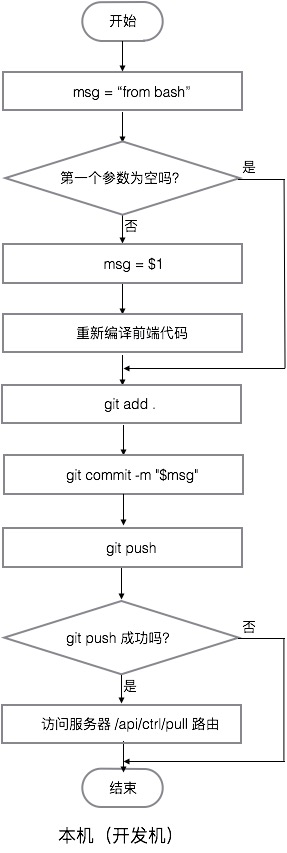
- 本机(开发机)
文件:push.sh
语言:Bash Script
环境:Bash
Desktop打包脚本
文件:package.json
语言:Bash Script
环境:Bash
使用:npm run script-name
"app:mac64": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -a x64 -p mac --insecure -n 古南师大刷脸签到 https://face.moyuyc.xyz/ -i desktop/logos/logo.icns --disable-dev-tools --disable-context-menu desktop",
"app:mac32": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -a ia32 -p mac --insecure -n 古南师大刷脸签到 \"https://face.moyuyc.xyz/\" -i desktop/logos/logo.icns --disable-dev-tools --disable-context-menu desktop",
"app:mac": "npm run app:mac32 & npm run app:mac64",
"app:win": "npm run app:win32 & npm run app:win64",
"app:win32": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -p win32 -a x64 --insecure -n 古南师大刷脸签到 \"https://face.moyuyc.xyz/\" -i desktop/logos/logo.png --disable-dev-tools --disable-context-menu desktop",
"app:win64": "set ELECTRON_MIRROR=https://npm.taobao.org/mirrors/electron/ && nativefier -c -p win32 -a ia32 --insecure -n 古南师大刷脸签到 \"https://face.moyuyc.xyz/\" -i desktop/logos/logo.png --disable-dev-tools --disable-context-menu desktop",一键搭建环境脚本
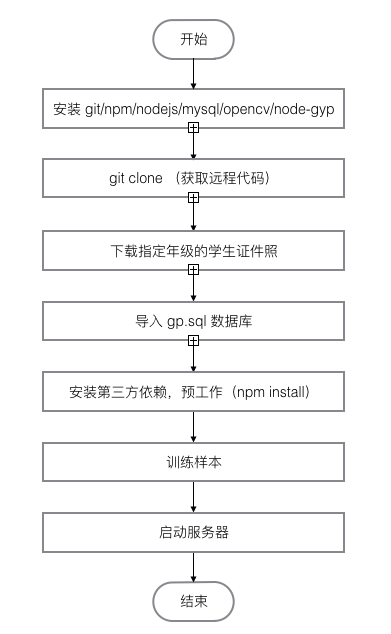
文件:start.sh
语言:Bash Script
环境:Bash
使用:./start.sh
特征脸人脸识别
人脸识别的任务本质就是:区别开一些输入信号(图像数据),将其划分进一些分类(人脸)中。 输入信号高度噪声(例如噪声是由不同引起的: 照明条件,姿势等),但输入图像不是完全随机的 尽管它们有差异,但是在任何输入信号中都存在模式。这样 在所有信号中可以观察到的模式可能是在面部识别领域。 任何面孔以及亲属中存在某些物体(眼睛,鼻子,嘴巴) 这些物体之间的距离。这些特征被称为特征脸 面部识别领域(或主要组成部分)。它们可以通过名为PCA(主成分分析法)的数学方法从原始图像数据中提取出来。 通过 PCA 可以能够将训练集的每个原图转化为相关的特征脸。PCA 一个重要的特征是能够组合特征脸来重构训练集中的原图。 记住特征脸不仅仅是面部的特征。所以说如果将每个特征脸按照正确的比例相加,原始脸部图像可以从特征脸重构出来。每个特征脸代表脸部都某些特征,其可能存在或不存在于原图中。如果特征以较高程度表现在原图中,则该特征对应的特征脸应该在特征脸集合相加的总和中,占用更大的比例。相反,特定的特征在原始图像中不存在(或几乎不存在),然后相应的特征脸应该贡献一个较小的(或根本不是)部分的总和。 因此,为了从特征脸重构原始图像,需要得到一系列特征脸的权重,也就是说,重构的原图图像等于所有特征面的总和,每个特征脸都有明确的权重。这个权重表示了指定特征(特征脸)在原图中所占的程度。
如果使用从原始图像提取的所有特征脸,可以重构来自特征脸的原始图像。但也可以只使用一部分特征脸,重建的图像是原始图像的近似值。然而,这样可以确保由于省略某些特征脸而造成的损失最小化,选择最重要的特征(特征脸)。
由于计算资源的匮乏,特征脸的部分选择(降维)是必要的。那这与人脸识别有什么关系呢?不仅可能从给定的一组权重的特征脸得到面部,但也可以用相反的方式,从特征脸和原人脸面部得到一组权重。使用这个权重可以确定两件重要的事情:
确定所讨论的图像是否是一张脸。 输入图像的权重与人脸图像(我们知道是人脸)的权重相差太大,则该输入不是人脸。 相似的脸(图像)具有相似的特征(特征脸)权重。 可以从所有可用的图像中提取权重,通过权重可以进行分组到集群。也就是说,具有相似权重的所有图像可能是类似的面孔。
算法概述
- 首先,将训练集的原始图像转换为一组特征脸 E。
- 然后,计算每个图像在 E 上的一组权重,保存在 W。
观察未知图像 X,计算取特征权重,存储在向量 Wx 中。之后,将Wx与知道他们是面孔(训练的权重W)的其他权重进行比较。一种方法是将每个权重向量视为空间中的一个点计算来自WX的权重向量与权重之间的平均距离D.未知图像的矢量WX(附录A中描述的欧几里德距离)。如果该平均距离超过某个阈值θ,那么未知图像WX的权重向量也与权重“分开”的脸。在这种情况下,未知X被认为不是脸。否则(如果X实际上是一个脸),它的权重向量WX被存储以备以后分类。最优经验性地确定阈值θ。
特征向量和特征值
矩阵的特征向量是一个向量,其与矩阵相乘,则结果总为该向量的整数倍。这个整数值是相应的特征向量的特征值。这种关系可以用公式 M × u = λ × u 来描述,其中u是矩阵M的特征向量,λ是相应的特征值。 特征向量具有以下属性:
- 它们只能用于方阵
- n×n矩阵中有n个特征向量(和相应的特征值)
- 所有特征向量都是垂直的,即彼此成直角
特征脸的计算(PCA 方法)
在本节中,使用PCA确定特征脸的原始方案将会 被呈现。 在本文范围内描述的算法是一个变体。在PCA中可以找到一个详细的(以及更理论的)PCA的描述(Pissarenko,2002,第70-72页)。
准备数据 在这个步骤中,应准备有人脸组成的训练集(Γi)
减去平均值 应当计算出来平均矩阵Ψ,然后从Γi中减去, 并将结果存储在变量Φi中
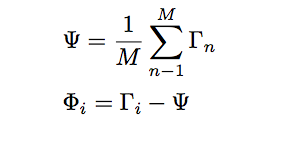
计算协方差矩阵 计算协方差矩阵 C,依据如下
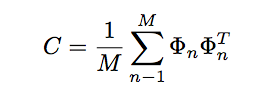
计算协方差的特征向量和特征值矩阵 在这个步骤中,特征向量(特征脸)ui和对应的特征值λi应该计算。特征向量(特征面)必须被归一化才能使它们成为单位向量,即长度为1。描述确定的特征向量和特征值求法在此省略,因为它属于标准的数学程式。
选择主要组件 从M个特征向量(特征脸)ui中,只应选择具有最高特征值的M0。特征值越高,特定特征向量描述的面的特征越多。可以省略具有低特征值的特征面,因为它们只解释了面部特征的一小部分。在确定M0特征脸ui之后,算法“训练”阶段结束。
改进原始算法
第5节描述的算法存在问题。协方差矩阵 在步骤3中(参见等式3)具有N 2×N 2的维数,因此将具有N 2 特征面和特征值。 对于256×256图像,这意味着必须计算65,536×65,536个矩阵,并计算65,536个特征面。在计算上,这并不是非常有效,因为大多数这些特征面对我们的任务没有用。所以,第三和第四步被Turk和Pentland(1991a)提出的方案所取代:
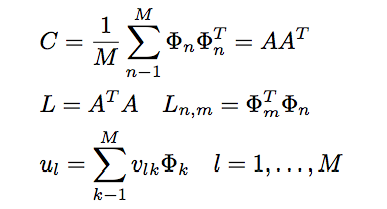
在步骤5中,相关联的特征值允许根据它们的有用性对特征面进行排序。 通常,我们将仅使用M个特征面的一个子集,具有最大特征值的M0特征面。
人脸分类
新的人脸(未知)分类至已知人脸中需要2个步骤。 首先,得到新人脸的特征脸,得到权重向量 ΩT(new)
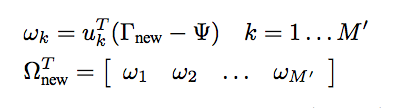
欧几里得距离
x 为被特征向量描述的任意实例。
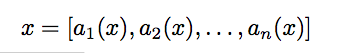
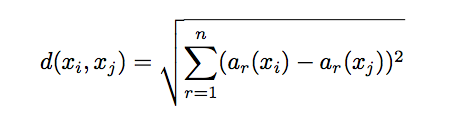
系统预览
- 学生签到
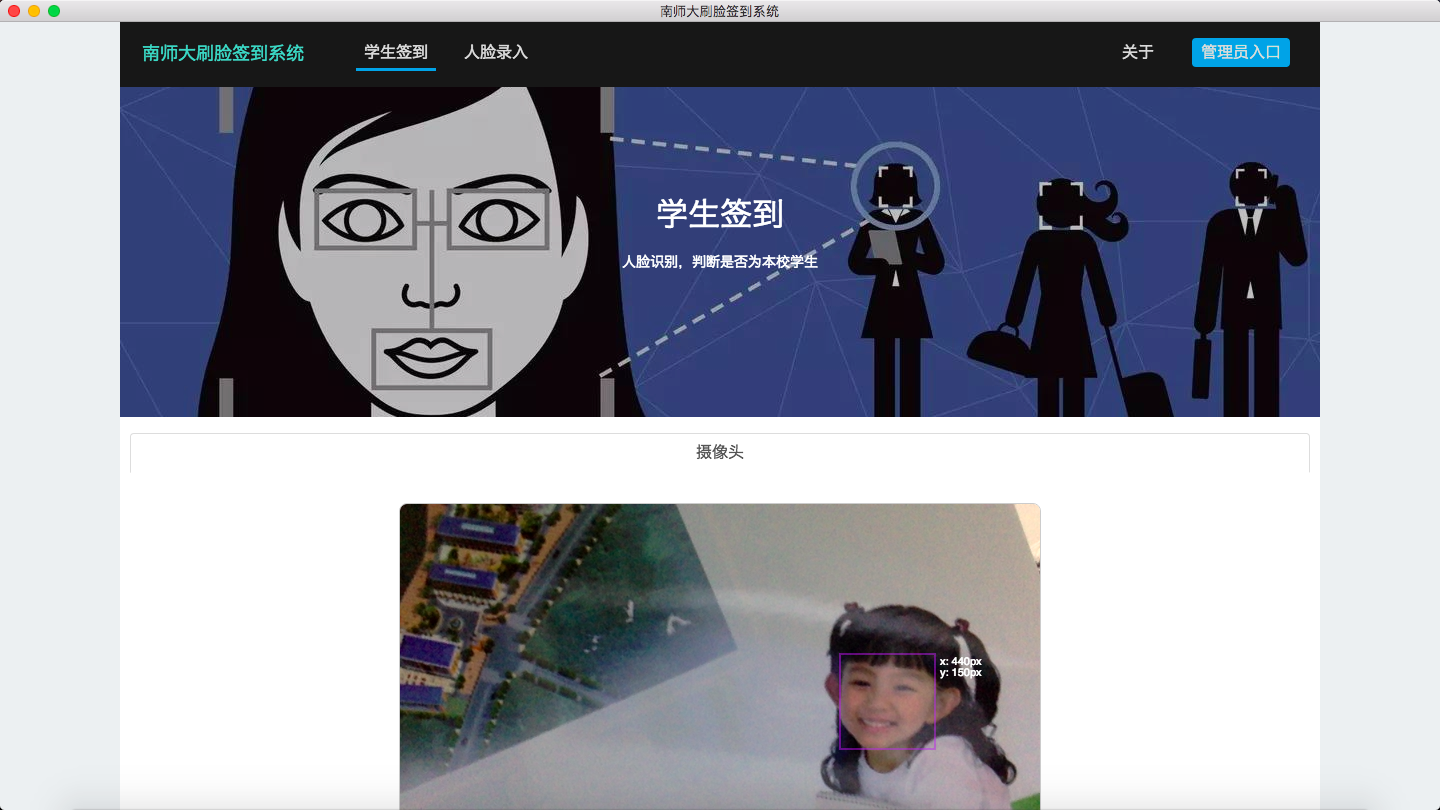
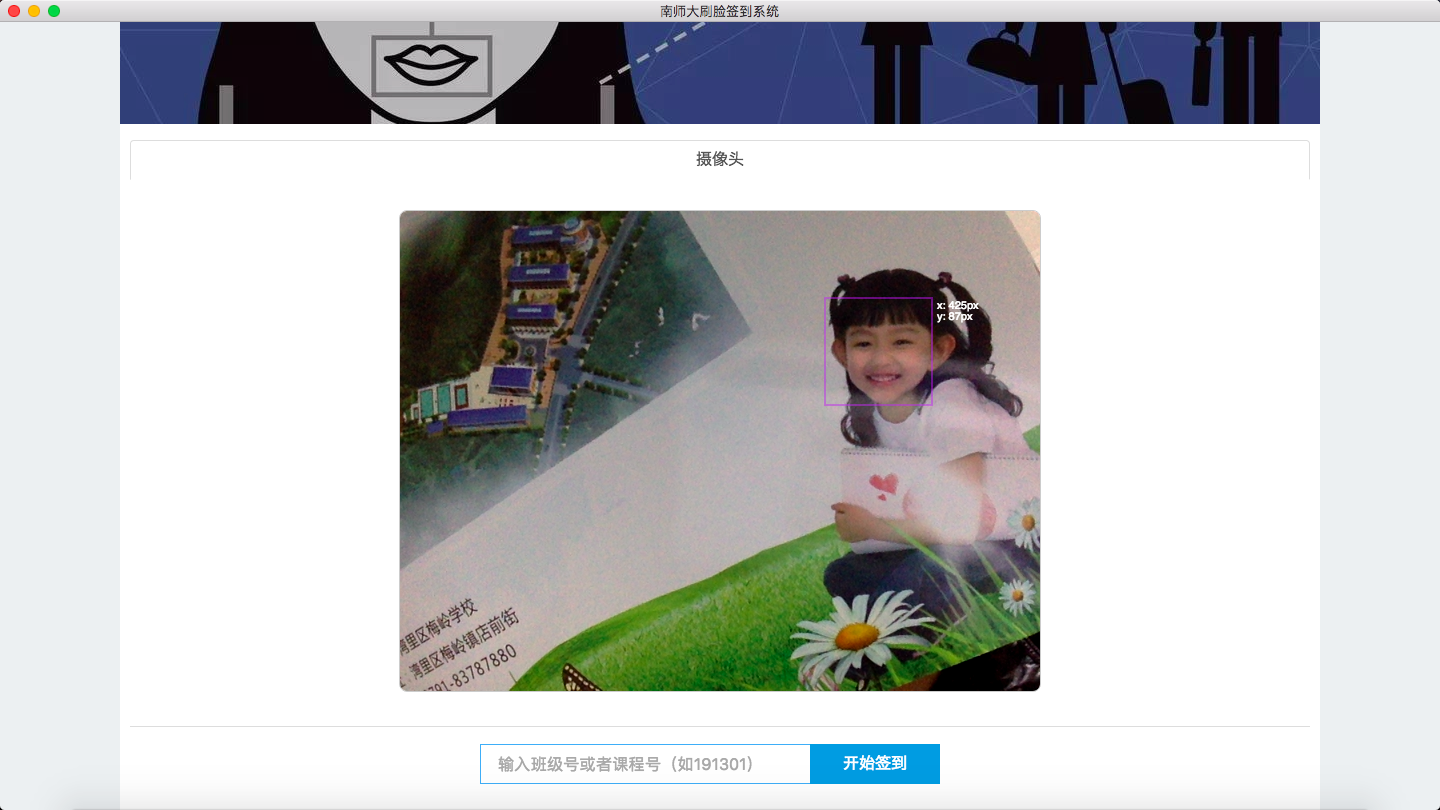
- 人脸录入
- 关于
- 管理员登录
- 管理员界面
总结与感谢
总结
经过几个月的毕业设计,对我各方面的影响都很大,对此我体会颇多。虽然这次设计成品还存在着很多问题,但我从中学到了不少知识。在开发过程中遇到的问题不计其数,其中最令人感到头痛的是一些不容易注意到的小错误,例如在编写 Node 与 C 系列addon 代码片段时,需要对 C 系列语言有比较功底才能从容实现,但自己本人 c 系列语言功底并不扎实,所以编写程序得到的效果一直不能达到预想的效果,后来通过参考 node-opencv 代码才渐渐进行开发;开发一个大的系统的时候,不管是个人还是团队,必须作好需求分析,建立好数据库,如果需求分析不成功,那到后面是很难做下去的,本系统的开发就遇到这样的情况,以至做了很多无用功,经常全部从新部署。一个好的需求分析报告将给系统带来很大的惊喜,它会很大程度上减少程序员的负担。 系统完成在后,发现做事情不但要独立自主的完成任务,也要通过周围的朋友或是网络资料库等获取信息,只有大量的使用周围方便的活资源,而不只依赖与书本上的例子,才能得到更大的进步,做起事情来才有事半功倍的效果。 本次毕业设计是针对我们大学四年来所学知识而进行的一次全面性的检验,它涵盖的知识面广,涉及到多个领域,需要我们具有较高的综合知识水平及较强的解决问题的能力。同时也是对我们工作能力,团队合作精神的一次考验。通过这次设计,一方面让我更进一步的熟悉和掌握了JavaScript、C++语言以及更深入的了解了opencv 的使用和一整套建站部署过程。另一方面在动手能力上有了很大的提高,以前学的知识只是“知识”,而现在是将“知识”转化成自身的本领,全面提高了自身解决具体问题的能力。
感谢
本论文是在杨老师悉心指导下完成的。从论文的选题,文献的查找到程序的设计,杨老师都给予了亲切的指导。在此深深感谢杨老师给予学生学业上的教导和生活上的关怀,老师严谨的治学态度和一丝不苟的工作作风给我极大的影响,不仅使我在静心完成论文的研究工作,而且也将勉励我今后刻苦学习和积极工作。同时本人对未知新理论的兴趣和积极探索,也很多来自于和导师交谈受到的启发。感谢我的父母和同学,他们的鼓励和支持是我踏实求学勤奋钻研的动力。大学四年时间是我人生的一个重要的阶段,在此期间,我所取得的每一滴进步无不得益于师长的教诲、朋友的帮助。为此,我要诚挚地向他们表达深深的谢意。
参考文献
[ 1 ] Chellappa R , Wilson C , Sirohey S. Human and machine rec2 ognition of faces: A survey. Proceedings of t he IEEE , 1995 , 83 (5) : 705-740
[ 2 ] Zhao W , Chellappa R , Rosenfeld A , Phillips P J. Face rec2 ognition : A literature survey. ACM Computation Survey , 2003 , 35 (4) : 399-458
[ 3 ] Li S Z , J ain A K. Handbook of Face Recognition. New York : Springer , 2005
[ 4 ] Zhou S , Chellappa R. Beyond a single still image : Face rec2 ognition from multiple still images and videos/ / Zhao W et al eds. Face Processing : Advanced Modeling and Met hods. New York : Academic Press , 2005: 1768-1828
[ 5 ] Shakhnarovich G , Fisher J W , Darrell T. Face recognition from long2term observations/ / Proceedings of t he European Conference on Computer Vision. Bari , 2002 : 851-868
[ 6 ] Liu X M , Chen T , Thornton S M. Eigenspace updating for non2stationary process and its application to face recognition. Pattern Recognition , 2003 , 36 (9) : 1945-1959
[ 7 ] Liu X M , Chen T. Video2based face recognition using adap2 tive hidden Markov models/ / Proceedings of t he IEEE Inter2 national Conference on Computer Vision and Pattern Recog2 nition. Madison , 2003 : 340-345
[ 8 ] Lee K C , Ho J , Yang M H , Kriegman D. Video2based face recognition using probabilistic appearance manifolds/ / Pro2 ceedings of t he International IEEE Conference on Computer Vision and Pattern Recognition. Madison , 2003 : 313-320
[ 9 ] Lee K C , Ho J , Yang M H , Kriegman D. Visual tracking and recognition using probabilistic appearance manifolds. Computer Vision and Image Understanding , 2005 , 99 ( 3) : 80-123
[ 10 ] Zhou S , Krueger V , Chellappa R. Probabilistic recognition of human faces from video. Computer Vision and Image Un2 derstanding , 2003 , 91 (1) : 2142245 [ 11 ] Zhou S , Chellappa R , Moghaddam B. Visual tracking and recognition using appearance2adaptive models in particle fil2 ters. IEEE Transactions on Image Processing , 2004 , 13:348-356
[ 11 ] Aggarwal G , Chowdhury A K R , Chellappa R. A system identification approach for video2based face recognition/ / Pro2 ceedings of t he IEEE International Conference on Pattern Recognition. Cambridge , 2004 : 232-249
[ 12 ] Arandjelovi’c O , Cipolla R. Face recognition from face motion manifolds using robust kernel resistor2average distance/ / Pro2 ceedings of t he IEEE Conference on Compute Vision and Pat2 ter Recognition workshop. Washington D. C , 2004 : 88-93
[ 13 ] Arandjelovi’c O , Shakhnarovich G , Fisher G , Cipolla R , Darrell T. Face recognition wit h image sets using manifold density divergence/ / Proceedings of t he IEEE Conference on Computer Vision and Pattern Recognition. San Diego , 2005 : 581-588
[ 14 ] Arandjelovi’c O , Cipolla R. A pose2wise linear illumination manifold model for face recognition using video. Computer Vision and Image Understanding , 2009 , 113 (1) : 113-125
[ 15 ] Yamaguchi O , Fukui K , Maeda K. Face recognition using temporal image sequence/ / Proceedings of t he IEEE Interna2 tional Conference on Automatic Face and Gesture Recogni2 tion. Nara , 1998 : 318-323 [ 16 ] Fukui K , Yamaguchi O. Face recognition using multi2view2 point patterns for robot vision/ / Proceedings of t he Interna2 tional Symposium of Robotics Research. Siena , Italy , 2003 : 192-220
[ 17 ] Nishiyama M , Yamaguchi O , Fukui K. Face Recognition wit h t he multiple constrained mutual subspace met hod/ / Pro2 ceedings of t he 5t h International Conference on Audio2 and Video2Based Biometric Person Aut hentication. New York , 2005 : 71-80
[ 18 ] Li J W , Wang Y H , Tan T N. Video2based face recognition using a metric of average Euclidean distance/ / Proceedings of t he 5t h Chinese Conference on Biometric Recognition. Guan2 gzhou , China , 2004 : 224-232
[ 19 ] Li J W , Wang Y H , Tan T N. Video2based face recognition using eart h mover’s distance/ / Proceedings of t he Interna2 tional Conference on Audio2 and Video2based person Aut hen2 tication. New York , 2005 : 229-239